Chapter 3 Single & Multiple Linear Regression
library(skimr)
library(kableExtra) # for the kable_styling function
library(tibble)
library(dplyr)
library(readr)
library(ggplot2)3.1 Single variable regression
The general equation for a linear regression model
\(y^i = \beta_{0} + \beta_{1} x^i + \epsilon^i\)
where:
- \(y^i\) is the \(i^{th}\) observation of the dependent variable
- \(\beta_{0}\) is the intercept coefficient
- \(\beta_{1}\) is the regression coefficient for the dependent variable
- \(x^i\) is the \(i^{th}\) observation of the independent variable
- \(\epsilon^i\) is the error term for the \(i^{th}\) observation. It basically is the difference in therm of y between the observed value and the estimated value. It is also called the residuals. A good model minimize these errors.1
Some ways to assess how good our model is to:
- compute the SSE (the sum of squared error)
- SSE = \((\epsilon^1)^2 + (\epsilon^2)^2 + \ldots + (\epsilon^n)^2\) = \(\sum_{i=1}^N \epsilon^i\)
- A good model will minimize SSE
- problem: SSE is dependent of N. SSE will naturally increase as N increase
- compute the RMSE (the root mean squared error)
- RMSE = \(\sqrt {\frac {SSE} {N}}\)
- Also a good model will minimize SSE
- It depends of the unit of the dependent variable. It is like the average error the model is making (in term of the unit of the dependent variable)
- compute \(R^2\)
- It compare the models to a baseline model
- \(R^2\) is unitless and universaly interpretable
- SST is the sum of the squared of the difference between the observed value and the mean of all the observed value
- \(R^2 = 1 - \frac {SSE} {SST}\)
We usually use r-squared to check the performance of a regression.
The conditions and assumptions to have a valid linear model are the same as for the t-test.
- linear relationship between dependent and independent variables. (scatterplot of dependent vs independent variables + scatterplot of residuals vs fitted). Also check here for outliers. Regression line and coefficient of regression are affected by outliers. Check it would make sense to remove them.
- Multivariate normality. Multiple regression assumes that the residuals are normally distributed. Visual check on the Q-Q plot.
- No Multicollinearity. Multiple regression assumes that the independent variables are not highly correlated with each other. Check correlation matrix and correlation plot. This assumption can also be tested using Variance Inflation Factor (VIF) values.
- Homoscedasticity. This assumption states that the variance of error terms are similar across the values of the independent variables. A plot of standardized residuals versus predicted values can show whether points are equally distributed across all values of the independent variables.
In our first linear regression, we’ll use the Wine dataset. Let’s load it and then have a quick look at its structure.
df = read_csv("dataset/Wine.csv")
skim(df)## Skim summary statistics
## n obs: 25
## n variables: 7
##
## ── Variable type:numeric ───────────────────────────────────────────────────
## variable missing complete n mean sd p0 p25
## Age 0 25 25 17.2 7.69 5 11
## AGST 0 25 25 16.51 0.68 14.98 16.2
## FrancePop 0 25 25 49694.44 3665.27 43183.57 46584
## HarvestRain 0 25 25 148.56 74.42 38 89
## Price 0 25 25 7.07 0.65 6.2 6.52
## WinterRain 0 25 25 605.28 132.28 376 536
## Year 0 25 25 1965.8 7.69 1952 1960
## p50 p75 p100 hist
## 17 23 31 ▇▆▆▇▆▆▃▆
## 16.53 17.07 17.65 ▂▃▃▇▆▆▆▅
## 50254.97 52894.18 54602.19 ▃▂▃▂▃▃▃▇
## 130 187 292 ▅▇▇▅▆▁▃▅
## 7.12 7.5 8.49 ▇▃▃▇▃▂▂▁
## 600 697 830 ▅▁▂▇▃▃▂▃
## 1966 1972 1978 ▆▃▆▇▆▆▆▇We use the lm function to create our linear regression model. We use AGST as the independent variable while the price is the dependent variable. 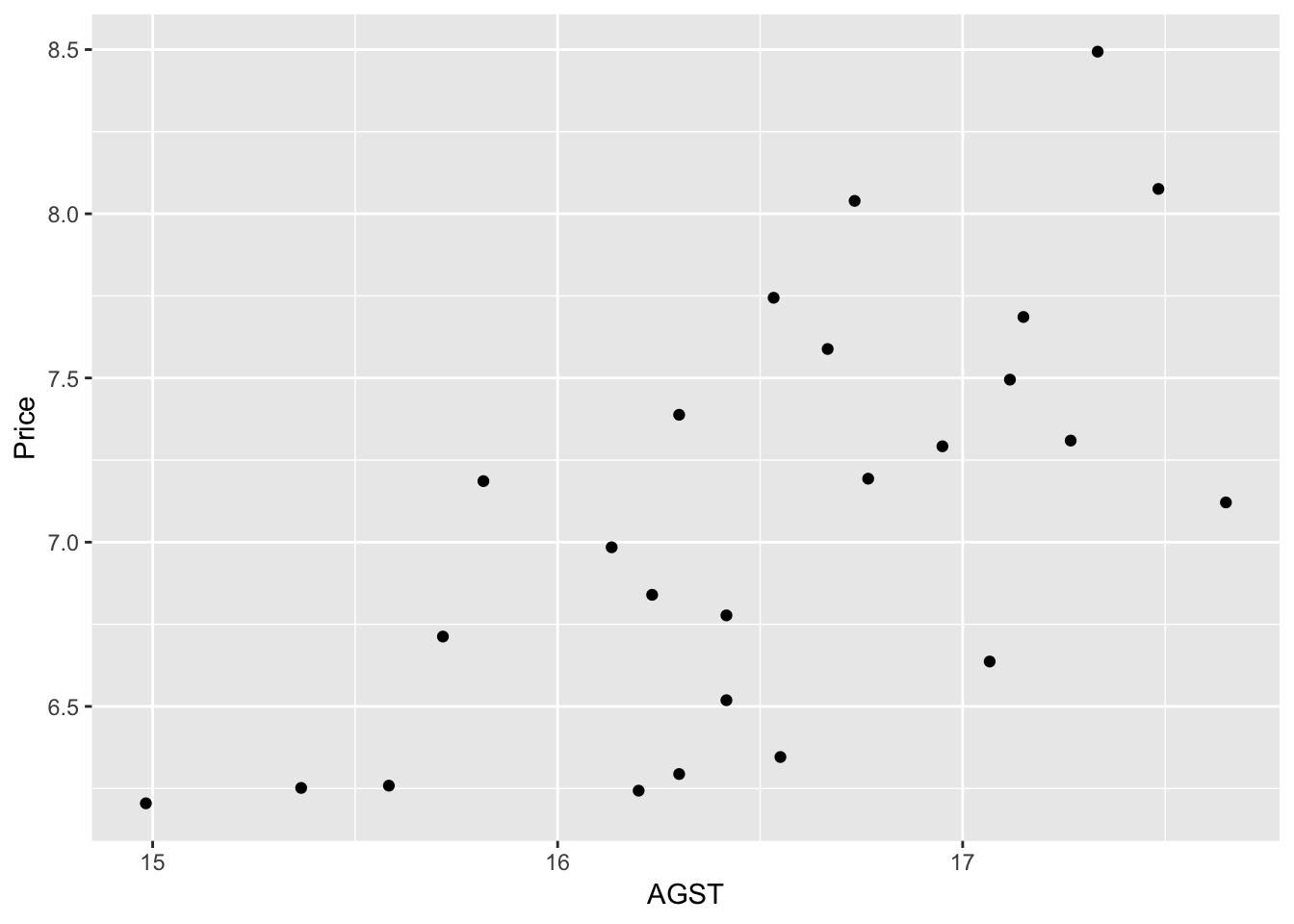
We can see a weak positive correlation between AGST and Price. The model would confirm that.
model_lm_df = lm(Price ~ AGST, data = df)
summary(model_lm_df)##
## Call:
## lm(formula = Price ~ AGST, data = df)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.78450 -0.23882 -0.03727 0.38992 0.90318
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -3.4178 2.4935 -1.371 0.183710
## AGST 0.6351 0.1509 4.208 0.000335 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.4993 on 23 degrees of freedom
## Multiple R-squared: 0.435, Adjusted R-squared: 0.4105
## F-statistic: 17.71 on 1 and 23 DF, p-value: 0.000335The summary function applied on the model is giving us important information. See below for a detailed explanation of it.
- the stars next to the predictor variable indicated how significant the variable is for our regression model
- it also gives us the value of the R^2 coefficient
We could have calculated the R^2 value in this way:
SSE = sum(model_lm_df$residuals^2)
SST = sum((df$Price - mean(df$Price))^2)
r_squared = 1 - SSE/SST
r_squared## [1] 0.4350232The low R^2 indicate our model does not explain much of the variance of the data.
We can now plot the observations and the line of regression; and see how the linear model fits the data.
ggplot(df, aes(AGST, Price)) +
geom_point(shape = 1, col = "blue") +
geom_smooth(method = "lm", col = "red")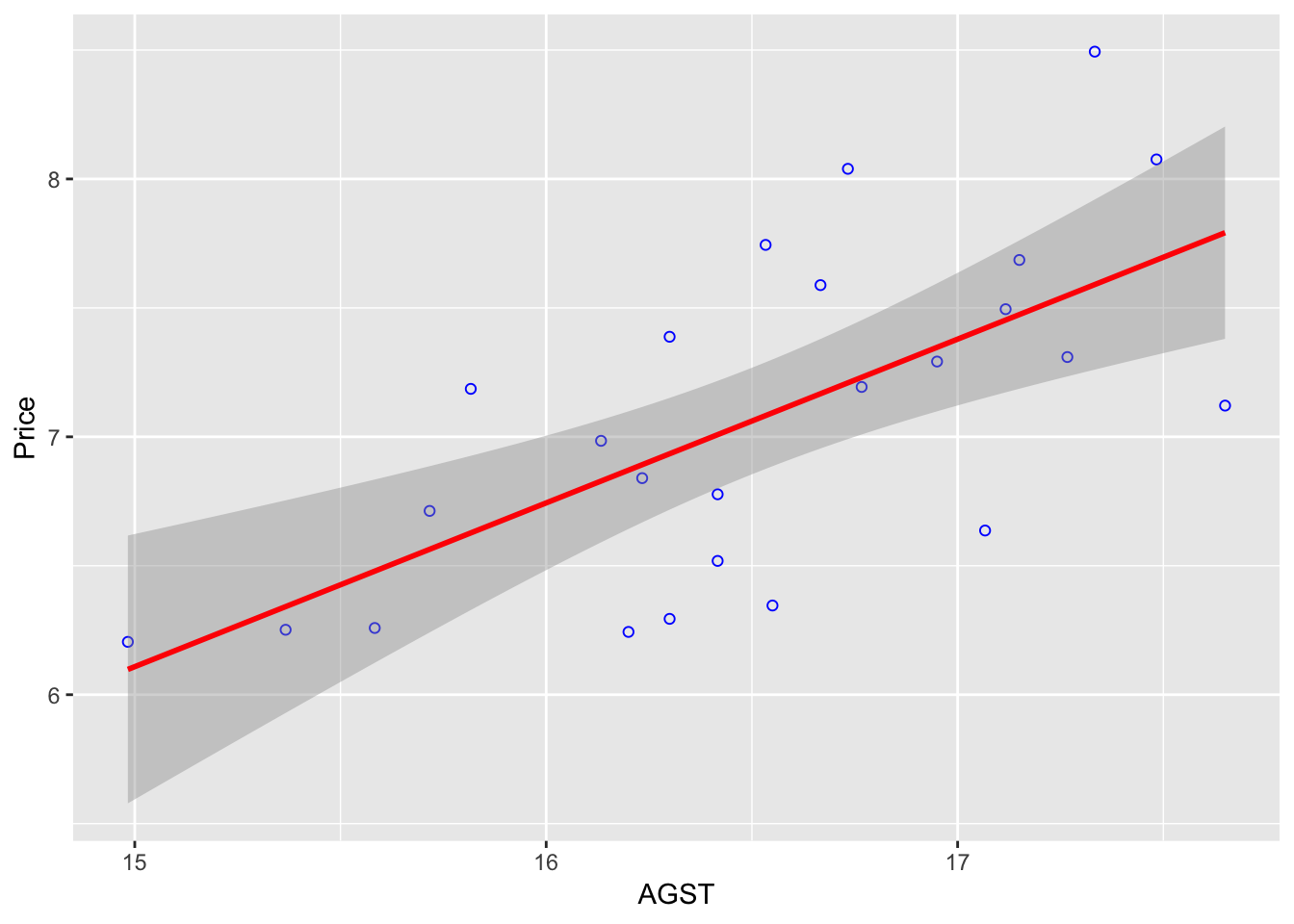 By default, the
By default, the geom_smooth() will use a 95% confidence interval (which is the grey-er area on the graph). There are 95% chance the line of regression will be within that zone for the whole population.
It is always nice to see how our residuals are distributed.
We use the ggplot2 library and the fortify function which transform the summary(model1) into a data frame usable for plotting.
model1 <- fortify(model_lm_df)
p <- ggplot(model1, aes(.fitted, .resid)) + geom_point()
p <- p + geom_hline(yintercept = 0, col = "red", linetype = "dashed")
p <- p + xlab("Fitted values") + ylab("Residuals") +
ggtitle("Plot of the residuals in function of the fitted values")
p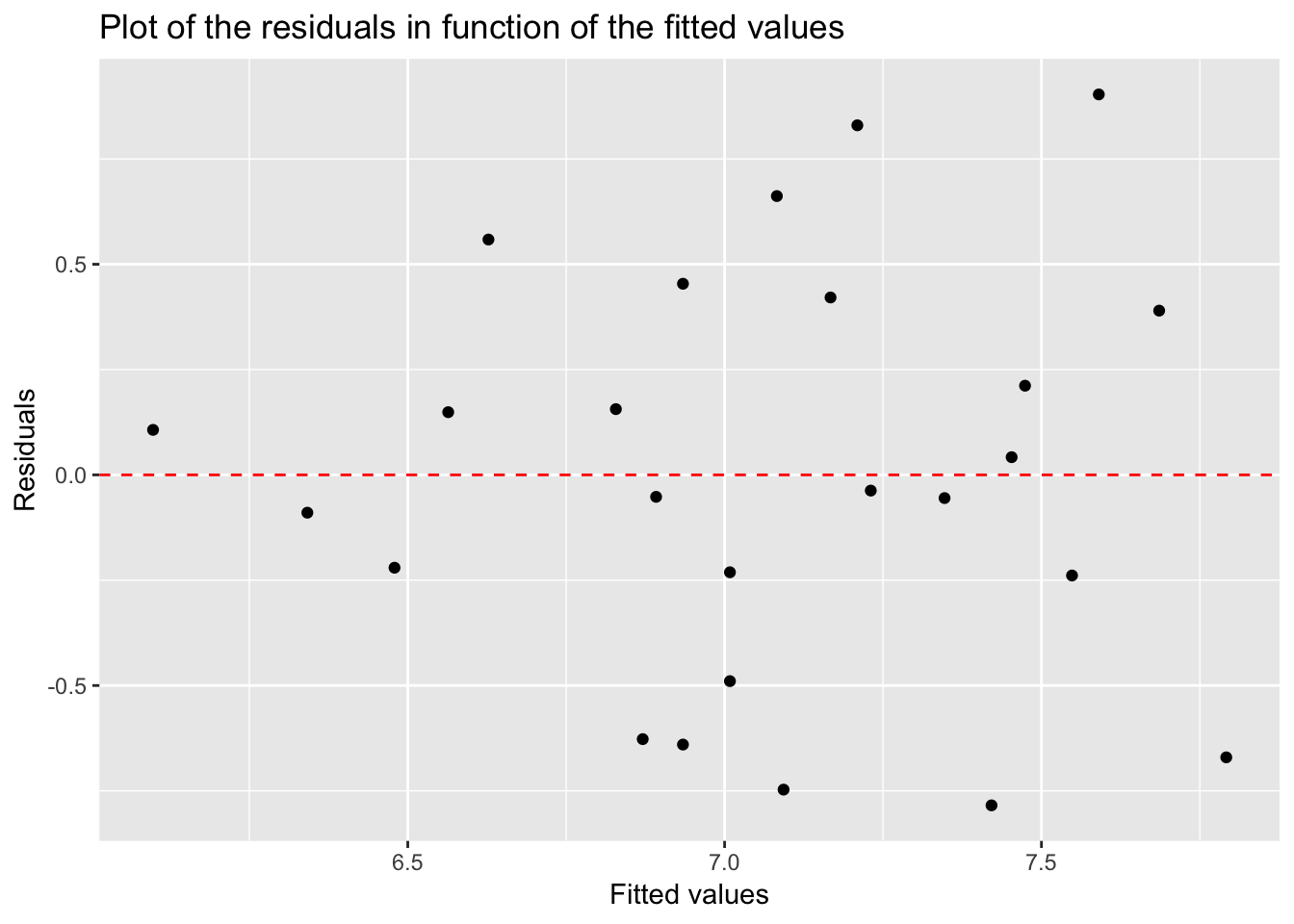
Residuals look normal: randonly scattered around the zero line.
3.2 Multi-variables regression
Instead of just considering one variable as predictor, we’ll add a few more variables to our model with the idea to increase its predictive ability. In our case, we are expecting an increased r-squared value.
We have to be cautious in adding more variables. Too many variable might give a high \(R^2\) on our training data, but this not be the case as we switch to our testing data. This is because of over-fitting and we will need to avoid this at all cost. We’ll check several ways we can use against overfitting.
The general equations can be expressed as
\(y^i = \beta_{0} + \beta_{1} x_{1}^i + \beta_{2} x_{2}^i + \ldots + \beta_{k} x_{k}^i + \epsilon^i\)
when there are k predictors variables.
There are a bit of trials and errors to make while trying to fit multiple variables into a model, but a rule of thumb would be to include most of the variable (all these that would make sense) and then take out the ones that are not very significant using the summary(modelx)
We are introducing 3 news libraries here besides the usual tidyverse.
library(corrr)
library(corrplot)
library(leaps)3.2.1 Predicting wine price (again!)
We continue here with the same dataset, wine.csv.
First, we can see how each variable is correlated with each other ones.
library(corrr)
d <- correlate(df)##
## Correlation method: 'pearson'
## Missing treated using: 'pairwise.complete.obs'd %>% shave() %>% fashion()## rowname Year Price WinterRain AGST HarvestRain Age FrancePop
## 1 Year
## 2 Price -.45
## 3 WinterRain .02 .14
## 4 AGST -.25 .66 -.32
## 5 HarvestRain .03 -.56 -.28 -.06
## 6 Age -1.00 .45 -.02 .25 -.03
## 7 FrancePop .99 -.47 -.00 -.26 .04 -.99By default, R uses the Pearson coefficient of correlation.
Multiple linear regression doesn’t handle well multicollinearity. In this case, we should remove variables that are too highly correlated. Age and Year are too highly correlated and it should be removed.
corrplot::corrplot(cor(df), type = "lower", order = "hclust", tl.col = "black", sig.level = 0.01)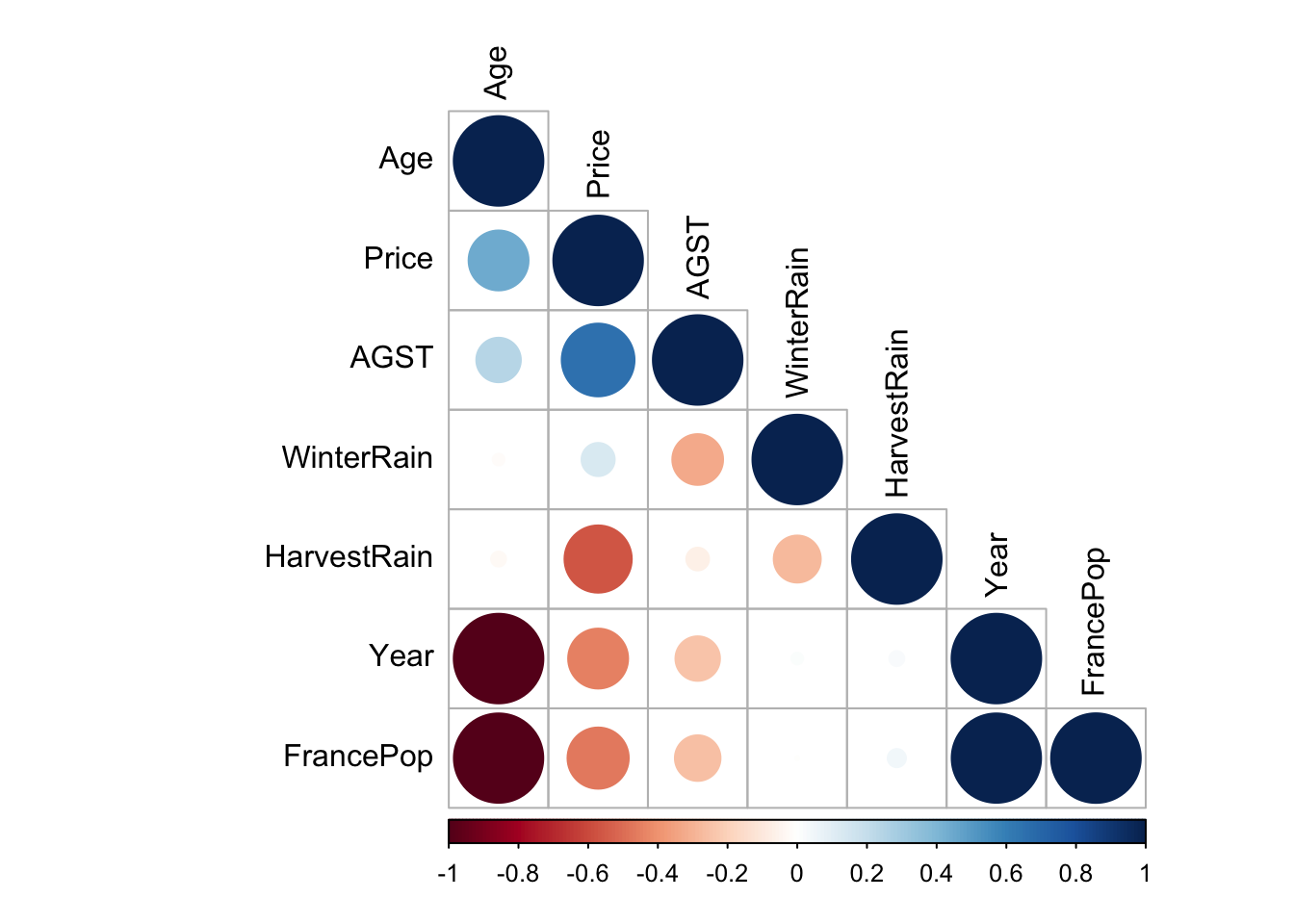
So let’s start by using all variables.
model2_lm_df <- lm(Price ~ Year + WinterRain + AGST + HarvestRain + Age + FrancePop, data = df)
summary(model2_lm_df)##
## Call:
## lm(formula = Price ~ Year + WinterRain + AGST + HarvestRain +
## Age + FrancePop, data = df)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.48179 -0.24662 -0.00726 0.22012 0.51987
##
## Coefficients: (1 not defined because of singularities)
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 7.092e-01 1.467e+02 0.005 0.996194
## Year -5.847e-04 7.900e-02 -0.007 0.994172
## WinterRain 1.043e-03 5.310e-04 1.963 0.064416 .
## AGST 6.012e-01 1.030e-01 5.836 1.27e-05 ***
## HarvestRain -3.958e-03 8.751e-04 -4.523 0.000233 ***
## Age NA NA NA NA
## FrancePop -4.953e-05 1.667e-04 -0.297 0.769578
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.3019 on 19 degrees of freedom
## Multiple R-squared: 0.8294, Adjusted R-squared: 0.7845
## F-statistic: 18.47 on 5 and 19 DF, p-value: 1.044e-06While doing so, we notice that the variable Age has NA. This is because it is so highly correlated with the variable year and FrancePop. This came in from our correlation plot. Also the variable FrancePop isn’t very predictive of the price of wine. So we can refine our models, by taking out these 2 variables, and as we’ll see, it won’t affect much our \(R^2\) value. Note that with multiple variables regression, it is important to look at the Adjusted R-squared as it take into consideration the amount of variables in the model.
model3_lm_df <- lm(Price ~ Year + WinterRain + AGST + HarvestRain, data = df)
summary(model3_lm_df)##
## Call:
## lm(formula = Price ~ Year + WinterRain + AGST + HarvestRain,
## data = df)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.45470 -0.24273 0.00752 0.19773 0.53637
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 44.0248601 16.4434570 2.677 0.014477 *
## Year -0.0239308 0.0080969 -2.956 0.007819 **
## WinterRain 0.0010755 0.0005073 2.120 0.046694 *
## AGST 0.6072093 0.0987022 6.152 5.2e-06 ***
## HarvestRain -0.0039715 0.0008538 -4.652 0.000154 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.295 on 20 degrees of freedom
## Multiple R-squared: 0.8286, Adjusted R-squared: 0.7943
## F-statistic: 24.17 on 4 and 20 DF, p-value: 2.036e-07We managed now to have a better r-squared than using only one predictive variable. Also by choosing better predictive variables we managed to increase our adjusted r-squared.
Although it isn’t now feasible to graph in 2D the Price in function of the other variables, we can still graph our residuals in 2D.
model3 <- fortify(model3_lm_df)
p <- ggplot(model3, aes(.fitted, .resid)) + geom_point() +
geom_hline(yintercept = 0, col = "red", linetype = "dashed") + xlab("Fitted values") +
ylab("Residuals") +
ggtitle("Plot of the residuals in function of the fitted values (multiple variables)")
p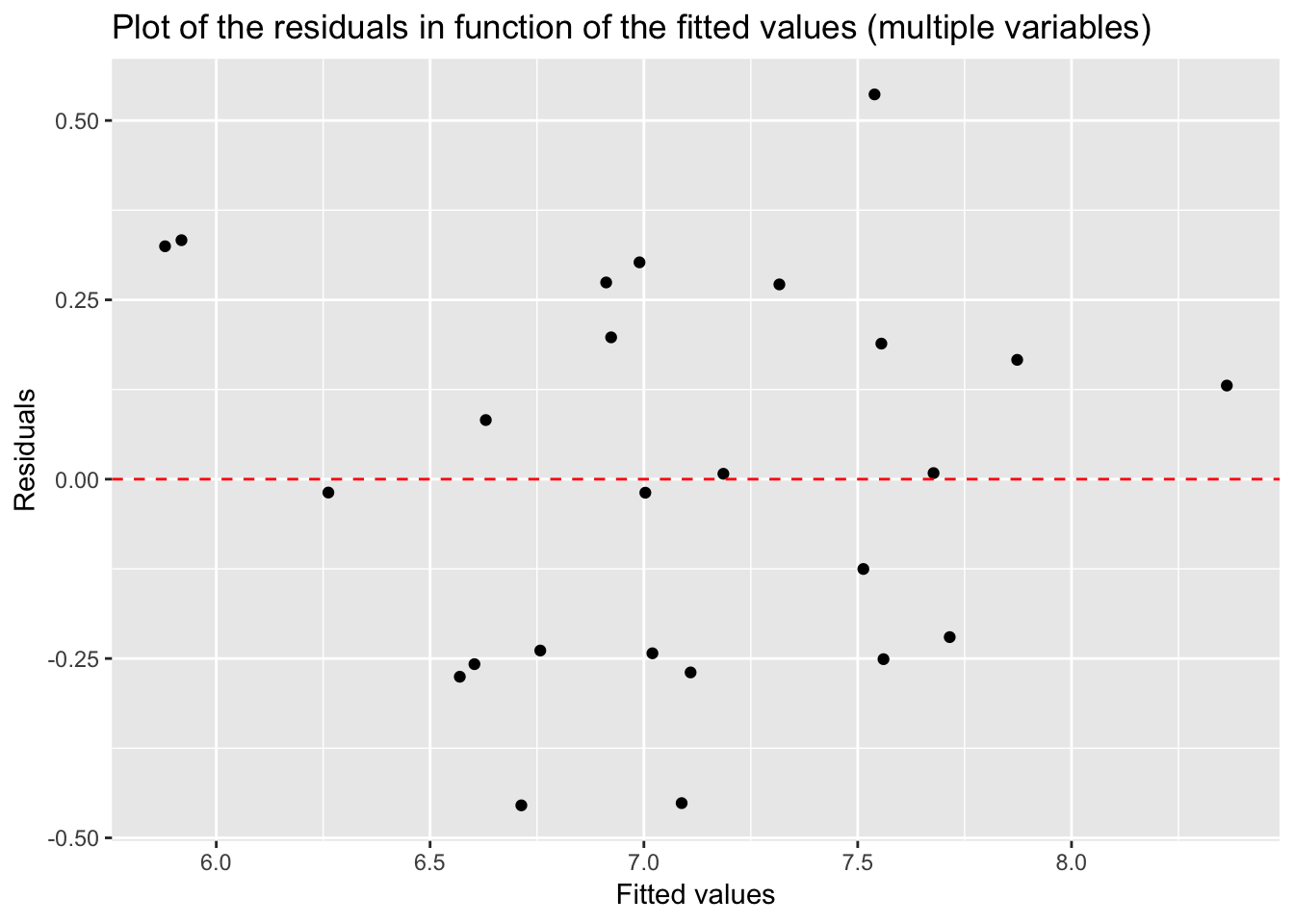
The plot of residuals look pretty normal with points randomly scattered around the 0 line.
3.3 Model diagnostic and evaluation
Let’s first on onto the explanations of the summary function on the regression model.
Call: The formula we have used for our model.
Coefficient – Estimate The coefficient Estimate is the value of the coefficient that is to be used in the equation. The coefficients for each of the independent variable has a meaning, for example, 0.0010755 for ‘WinterRain’ means that for every 1 unit change in ‘WinterRain’, the value of ‘Price‘ increases by 0.0010755.
Coefficient – Standard Error The coefficient Standard Error measures the average amount that the coefficient estimates vary from the actual average value of our response variable. We need this to be minimal for the variable to be able to predict accurately.
Coefficient – t value: The coefficient t-value measures how many standard deviations our coefficient estimate can be far away from 0. We want this value to be high so that we can reject the null hypothesis (H0) which is ‘there is no relationship between dependent and independent variables’.
Coefficient – Pr(>t): The Pr(>t) is computed from the t values. This is used for rejecting the Null Hypothesis (H00) stated above. Normally, the value for this less than 0.05 or 5% is considered to be the cut-off point for rejecting H0.
Residuals: Residuals are the next component in the model summary. Residuals are the difference between the predicted values by the model and the actual values in the dataset. For the model to be good, the residuals should be normally distributed.
Adjusted R-squared:
Adjusted R-squared is considered for evaluating model accuracy when the number of independent variables is greater than 1. Adjusted R-squared adjusts the number of variables considered in the model and is the preferred measure for evaluating the model goodness.
F-Statistic: F-statistic is used for finding out if there exists any relationship between our independent (predictor) and the dependent (response) variables. Normally, the value of F-statistic greater than one can be used for rejecting the null hypothesis (H0: There is no relationship between Employed and other independent variables). For our model, the value of F-statistic, 330.6 is very high because of the limited data points. The p-value in the output for F-statistic is evaluated the same way we use the Pr(>t) value in the coefficients output. For the p-value, we can reject the null hypothesis (H0) as p-value < 0.05.
There is no established relationship between the two. R-squared tells how much variation in the response variable is explained by the predictor variables while p-value tells if the predictors used in the model are able to explain the response variable or not. If p-value < 0.05 (for 95% confidence), then the model is considered to be good.
- low R-square and low p-value (p-value <= 0.05): This means that the model doesn’t explain much of the variation in the response variable, but still this is considered better than having no model to explain the response variable as it is significant as per the p-value.
- low R-square and high p-value (p-value > 0.05): This means that model doesn’t explain much variation in the data and is not significant. We should discard such model as this is the worst scenario.
- high R-square and low p-value: This means that model explains a lot of variation in the data and is also significant. This scenario is best of the four and the model is considered to be good in this case.
- high R-square and high p-value: This means that variance in the data is explained by the model but it is not significant. We should not use such model for predictions.
Here are the nessary conditions for a linear regression model to be valid. Hence, these are the assumptions made when doing a linear regression.
- Linear Relationship.
The plot of the residuals should show the data points randomly scattered around the 0 line.
This plot shows if residuals have non-linear patterns. There could be a non-linear relationship between predictor variables and an outcome variable and the pattern could show up in this plot if the model doesn’t capture the non-linear relationship. If you find equally spread residuals around a horizontal line without distinct patterns, that is a good indication you don’t have non-linear relationships.
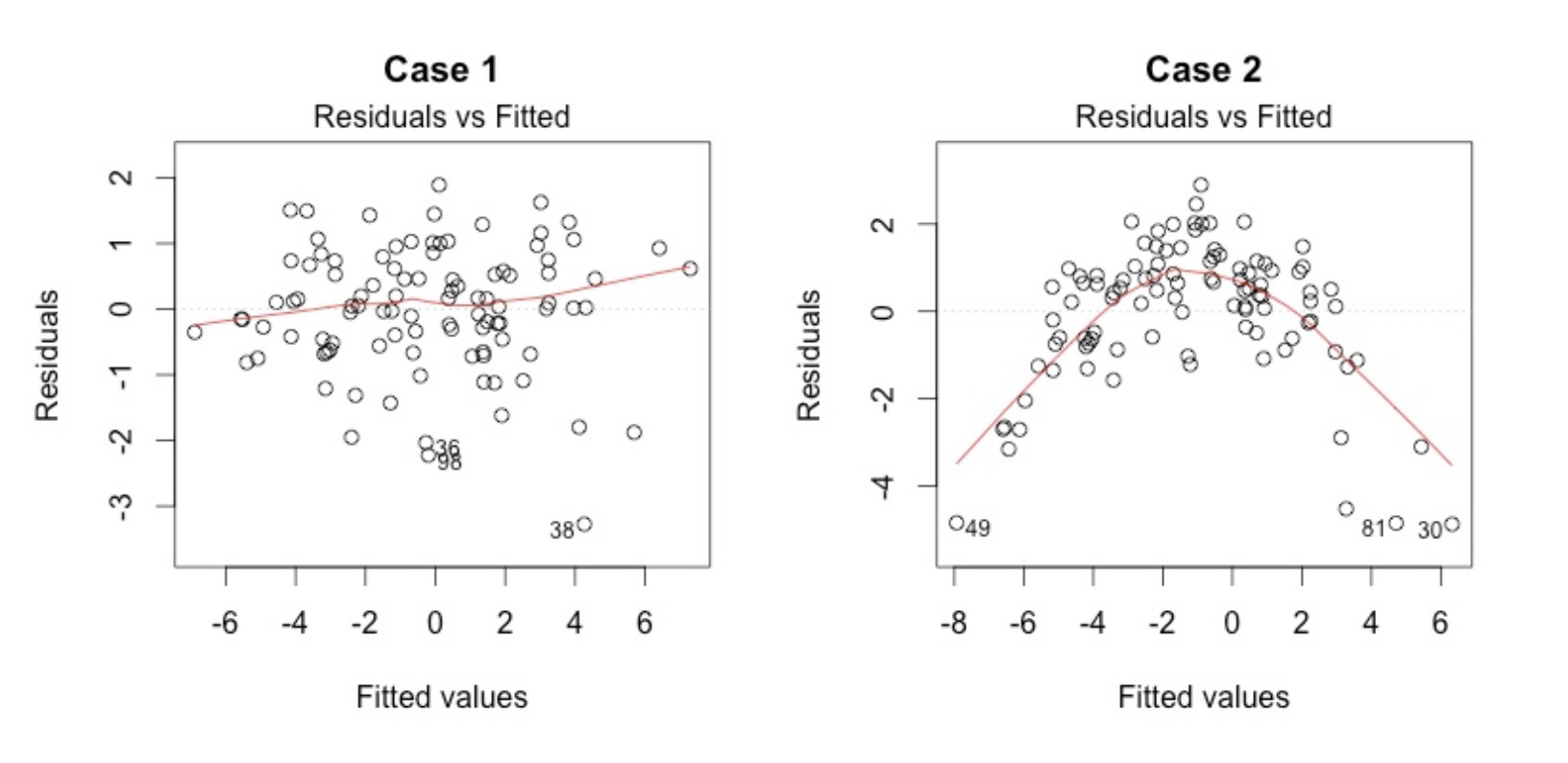
Good Vs Bad residuals plot
There isn’t any distinctive pattern in Case 1, but there is a parabola in Case 2, where the non-linear relationship was not explained by the model and was left out in the residuals.
Multivariate normality. The multiple linear regression analysis requires that the errors between observed and predicted values (i.e., the residuals of the regression) should be normally distributed. This assumption may be checked by looking at a histogram or a Q-Q-Plot. Normality can also be checked with a goodness of fit test (e.g., the Kolmogorov-Smirnov test), though this test must be conducted on the residuals themselves.
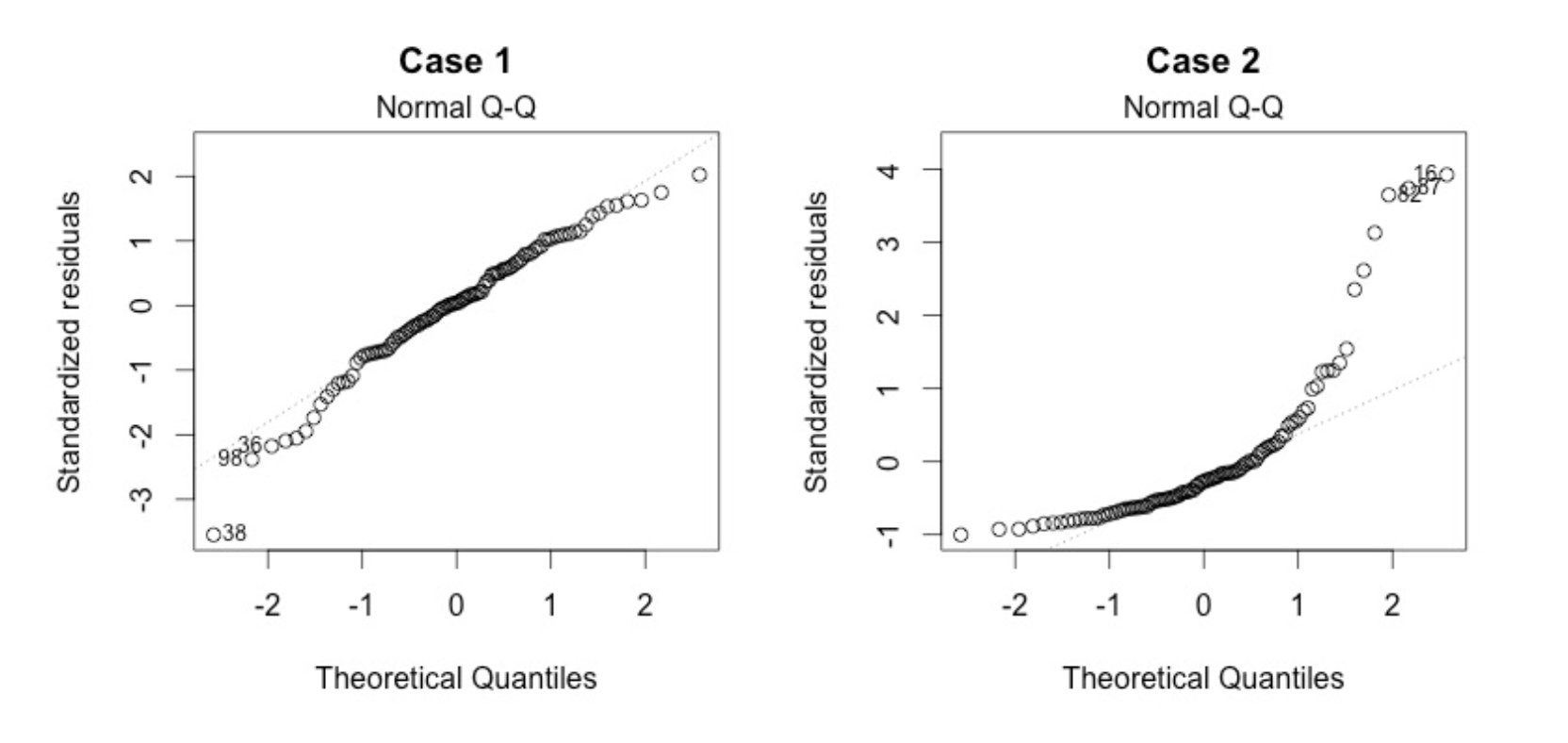
- No Multicollinearity. Multicollinearity may be tested with these central criteria:
- Correlation matrix. When computing the matrix of Pearson’s Bivariate Correlation among all independent variables the correlation coefficients need to be smaller than 1.
- Variance Inflation Factor (VIF) – the variance inflation factor of the linear regression is defined as VIF = 1/T. Tolerance (T) is defined as T = 1 – R². With VIF > 10 there is an indication that multicollinearity may be present; with VIF > 100 there is certainly multicollinearity among the variables. If multicollinearity is found in the data, centering the data (that is deducting the mean of the variable from each score) might help to solve the problem. However, the simplest way to address the problem is to remove independent variables with high VIF values.
- Homoscedasticity. A scatterplot of residuals versus predicted values is good way to check for homoscedasticity. There should be no clear pattern in the distribution; if there is a cone-shaped pattern (as shown below), the data is heteroscedastic. If the data are heteroscedastic, a non-linear data transformation or addition of a quadratic term might fix the problem.
This plot shows if residuals are spread equally along the ranges of predictors. This is how you can check the assumption of equal variance (homoscedasticity). It’s good if you see a horizontal line with equally (randomly) spread points.
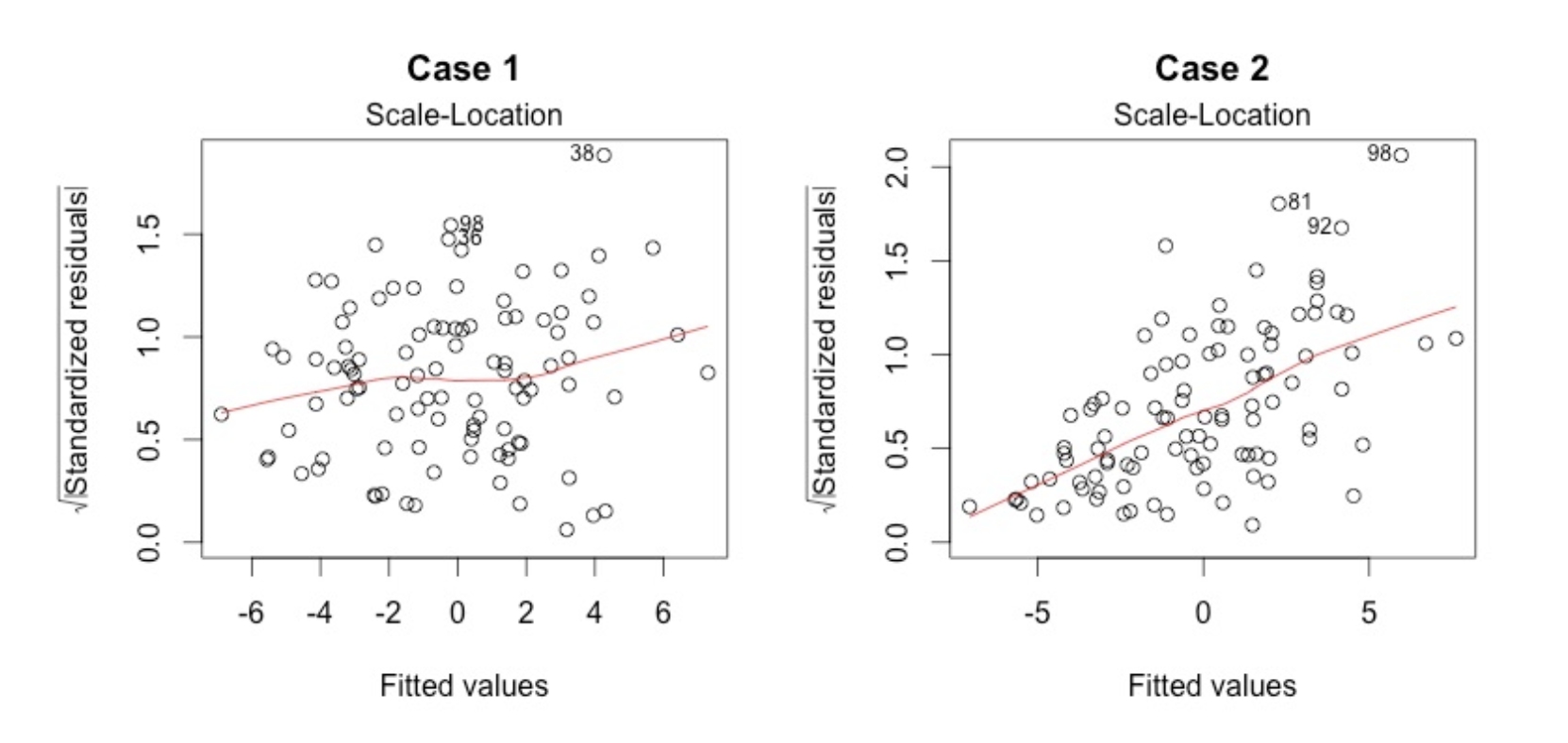
In Case 2, the residuals begin to spread wider along the x-axis. Because the residuals spread wider and wider, the red smooth line is not horizontal and shows a steep angle in Case 2.
3.4 Final example - Boston dataset - with backward elimination
On this last example we’ll use a more systemic way to find out which variables should be chosen into our models.
df <- read_csv("dataset/Boston.csv")
skimr::skim(df)## Skim summary statistics
## n obs: 333
## n variables: 14
##
## ── Variable type:numeric ───────────────────────────────────────────────────
## variable missing complete n mean sd p0 p25 p50
## AGE 0 333 333 68.23 28.13 6 45.4 76.7
## BLACK 0 333 333 359.47 86.58 3.5 376.73 392.05
## CHAS 0 333 333 0.06 0.24 0 0 0
## CRIM 0 333 333 3.36 7.35 0.0063 0.079 0.26
## DIS 0 333 333 3.71 1.98 1.13 2.12 3.09
## INDUS 0 333 333 11.29 7 0.74 5.13 9.9
## LSTAT 0 333 333 12.52 7.07 1.73 7.18 10.97
## MEDV 0 333 333 22.77 9.17 5 17.4 21.6
## NOX 0 333 333 0.56 0.11 0.39 0.45 0.54
## PTRATIO 0 333 333 18.45 2.15 12.6 17.4 19
## RAD 0 333 333 9.63 8.74 1 4 5
## RM 0 333 333 6.27 0.7 3.56 5.88 6.2
## TAX 0 333 333 409.28 170.84 188 279 330
## ZN 0 333 333 10.69 22.67 0 0 0
## p75 p100 hist
## 93.8 100 ▁▂▂▂▂▂▃▇
## 396.24 396.9 ▁▁▁▁▁▁▁▇
## 0 1 ▇▁▁▁▁▁▁▁
## 3.68 73.53 ▇▁▁▁▁▁▁▁
## 5.12 10.71 ▇▆▅▃▂▁▁▁
## 18.1 27.74 ▅▅▃▁▁▇▁▁
## 16.42 37.97 ▅▇▆▃▂▁▁▁
## 25 50 ▂▅▇▇▂▂▁▁
## 0.63 0.87 ▇▇▇▆▃▅▁▁
## 20.2 21.2 ▁▂▁▂▃▃▂▇
## 24 24 ▃▇▂▁▁▁▁▅
## 6.59 8.72 ▁▁▂▇▇▂▁▁
## 666 711 ▅▇▂▅▁▁▁▇
## 12.5 100 ▇▁▁▁▁▁▁▁Here is the list of variables with their meaning.
- CRIM per capita crime rate by town
- ZN proportion of residential land zoned for lots over 25,000 sq.ft.
- INDUS proportion of non-retail business acres per town
- CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
- NOX nitric oxides concentration (parts per 10 million)
- RM average number of rooms per dwelling
- AGE proportion of owner-occupied units built prior to 1940
- DIS weighted distances to five Boston employment centres
- RAD index of accessibility to radial highways
- TAX full-value property-tax rate per $10,000
- PTRATIO pupil-teacher ratio by town
- B 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
- LSTAT % lower status of the population
- MEDV Median value of owner-occupied homes in $1000’s
Let’s make the necessary adjustment in variable types
df$CHAS <- factor(df$CHAS)A quick check on how correlated are our variables.
corrplot(cor(df %>% select(-CHAS)), type = "lower", order = "hclust", tl.col = "black", sig.level = 0.01)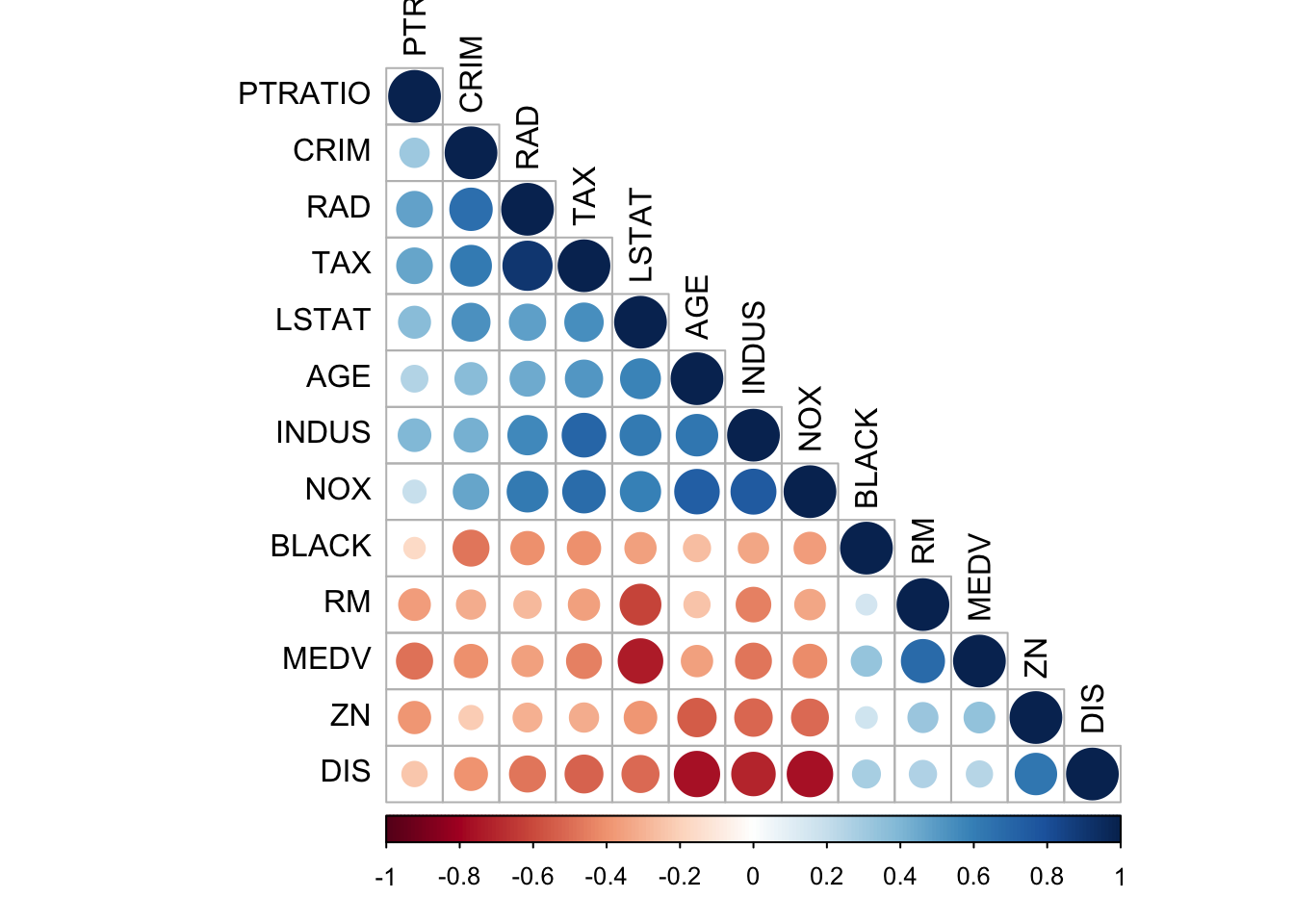
correlate(df %>% select(-CHAS)) %>% shave() %>% fashion()##
## Correlation method: 'pearson'
## Missing treated using: 'pairwise.complete.obs'## rowname CRIM ZN INDUS NOX RM AGE DIS RAD TAX PTRATIO BLACK
## 1 CRIM
## 2 ZN -.21
## 3 INDUS .42 -.52
## 4 NOX .46 -.50 .75
## 5 RM -.31 .33 -.44 -.34
## 6 AGE .38 -.54 .64 .74 -.25
## 7 DIS -.40 .64 -.70 -.77 .27 -.76
## 8 RAD .67 -.30 .57 .61 -.27 .45 -.48
## 9 TAX .62 -.31 .71 .67 -.36 .51 -.53 .90
## 10 PTRATIO .31 -.38 .39 .19 -.37 .26 -.23 .47 .47
## 11 BLACK -.48 .17 -.34 -.37 .16 -.27 .28 -.41 -.41 -.16
## 12 LSTAT .53 -.39 .61 .60 -.62 .59 -.51 .48 .54 .37 -.36
## 13 MEDV -.41 .34 -.47 -.41 .69 -.36 .25 -.35 -.45 -.48 .34
## LSTAT MEDV
## 1
## 2
## 3
## 4
## 5
## 6
## 7
## 8
## 9
## 10
## 11
## 12
## 13 -.74yo <- correlate(df %>% select(-CHAS)) %>% shave() %>% fashion()##
## Correlation method: 'pearson'
## Missing treated using: 'pairwise.complete.obs'kable(yo, format = "html") %>% kable_styling()| rowname | CRIM | ZN | INDUS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | BLACK | LSTAT | MEDV |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CRIM | |||||||||||||
| ZN | -.21 | ||||||||||||
| INDUS | .42 | -.52 | |||||||||||
| NOX | .46 | -.50 | .75 | ||||||||||
| RM | -.31 | .33 | -.44 | -.34 | |||||||||
| AGE | .38 | -.54 | .64 | .74 | -.25 | ||||||||
| DIS | -.40 | .64 | -.70 | -.77 | .27 | -.76 | |||||||
| RAD | .67 | -.30 | .57 | .61 | -.27 | .45 | -.48 | ||||||
| TAX | .62 | -.31 | .71 | .67 | -.36 | .51 | -.53 | .90 | |||||
| PTRATIO | .31 | -.38 | .39 | .19 | -.37 | .26 | -.23 | .47 | .47 | ||||
| BLACK | -.48 | .17 | -.34 | -.37 | .16 | -.27 | .28 | -.41 | -.41 | -.16 | |||
| LSTAT | .53 | -.39 | .61 | .60 | -.62 | .59 | -.51 | .48 | .54 | .37 | -.36 | ||
| MEDV | -.41 | .34 | -.47 | -.41 | .69 | -.36 | .25 | -.35 | -.45 | -.48 | .34 | -.74 |
model_mlr_df <- lm(MEDV ~ ., data = df)
model_bwe_df <- regsubsets(formula(model_mlr_df), data = df, method = "backward")
summary(model_mlr_df)##
## Call:
## lm(formula = MEDV ~ ., data = df)
##
## Residuals:
## Min 1Q Median 3Q Max
## -11.6174 -2.8741 -0.6261 1.6553 24.5250
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 34.045438 6.296131 5.407 1.26e-07 ***
## CRIM -0.052489 0.053799 -0.976 0.32997
## ZN 0.047445 0.016916 2.805 0.00534 **
## INDUS 0.053855 0.074238 0.725 0.46871
## CHAS1 3.784864 1.149874 3.292 0.00111 **
## NOX -15.739657 4.855773 -3.241 0.00131 **
## RM 3.768832 0.520066 7.247 3.23e-12 ***
## AGE -0.004627 0.016885 -0.274 0.78426
## DIS -1.548823 0.264283 -5.860 1.15e-08 ***
## RAD 0.328967 0.081861 4.019 7.31e-05 ***
## TAX -0.012866 0.004519 -2.847 0.00469 **
## PTRATIO -0.856976 0.165343 -5.183 3.88e-07 ***
## BLACK 0.011666 0.003597 3.243 0.00131 **
## LSTAT -0.600315 0.063841 -9.403 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 4.834 on 319 degrees of freedom
## Multiple R-squared: 0.7331, Adjusted R-squared: 0.7223
## F-statistic: 67.41 on 13 and 319 DF, p-value: < 2.2e-16plot(model_bwe_df, scale = "adjr2")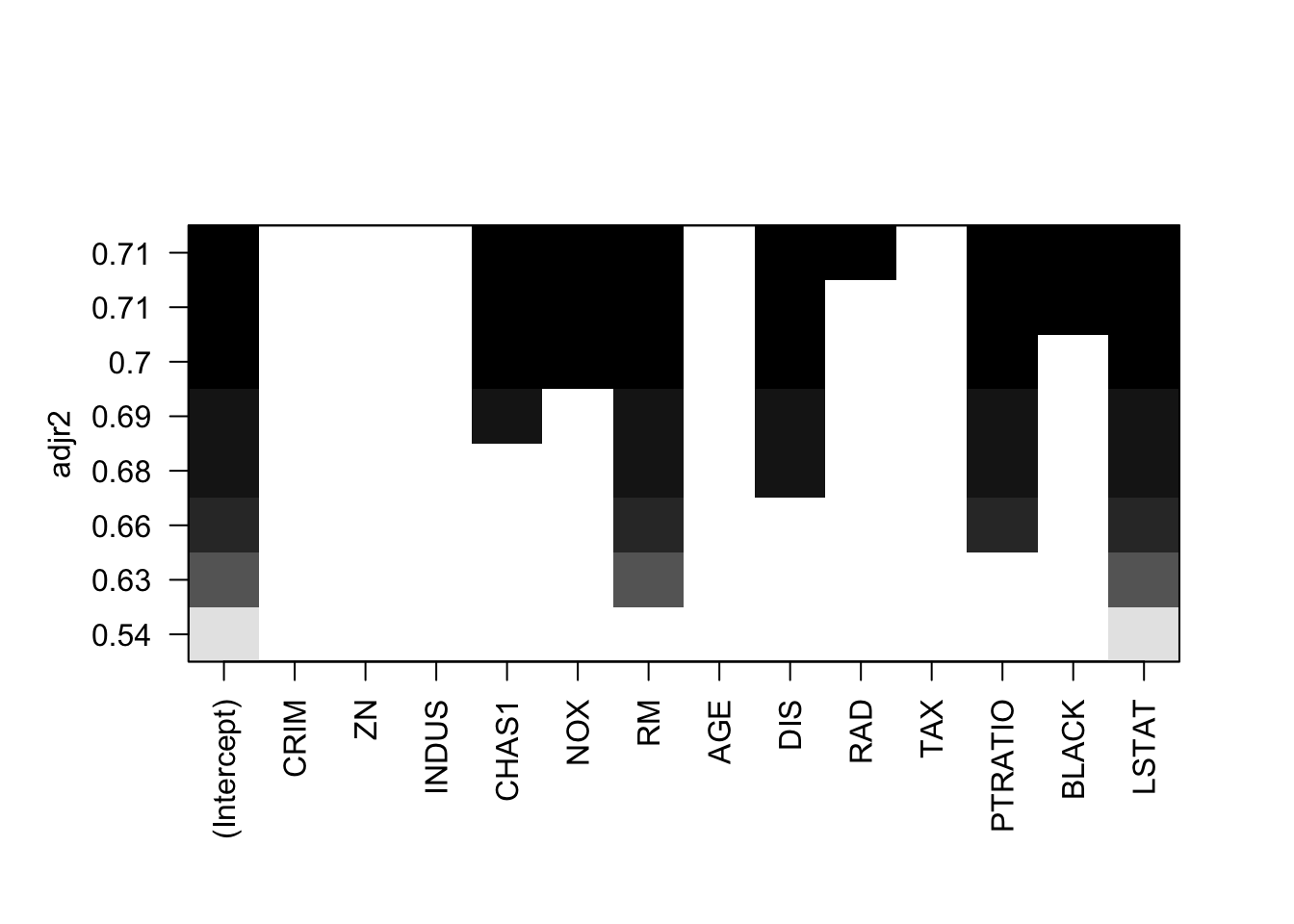
Ideally, the model should consider the following variables
model2_mlr_df <- lm(MEDV ~ CRIM + NOX + RM + DIS + RAD + PTRATIO + BLACK + LSTAT, data = df)
summary(model2_mlr_df)##
## Call:
## lm(formula = MEDV ~ CRIM + NOX + RM + DIS + RAD + PTRATIO + BLACK +
## LSTAT, data = df)
##
## Residuals:
## Min 1Q Median 3Q Max
## -12.0039 -3.1223 -0.6353 1.8782 25.2095
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 32.703270 6.414135 5.099 5.83e-07 ***
## CRIM -0.041182 0.055041 -0.748 0.454880
## NOX -18.097931 4.535787 -3.990 8.17e-05 ***
## RM 4.194258 0.508532 8.248 4.09e-15 ***
## DIS -1.288755 0.219996 -5.858 1.15e-08 ***
## RAD 0.166232 0.052295 3.179 0.001622 **
## PTRATIO -1.080124 0.157349 -6.864 3.41e-11 ***
## BLACK 0.013020 0.003689 3.529 0.000477 ***
## LSTAT -0.604600 0.061989 -9.753 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 4.99 on 324 degrees of freedom
## Multiple R-squared: 0.7112, Adjusted R-squared: 0.7041
## F-statistic: 99.76 on 8 and 324 DF, p-value: < 2.2e-163.4.1 Model diagmostic
To check that we have a linear relationship between the numerical explanatory variables and the response variable, we create a scatter plot with the variable and the residuals
df2 <- tibble(x = df$MEDV, residuals = model2_mlr_df$residuals, fitted = model2_mlr_df$fitted.values)
ggplot(df2, aes(x = x, y = residuals)) +
geom_jitter()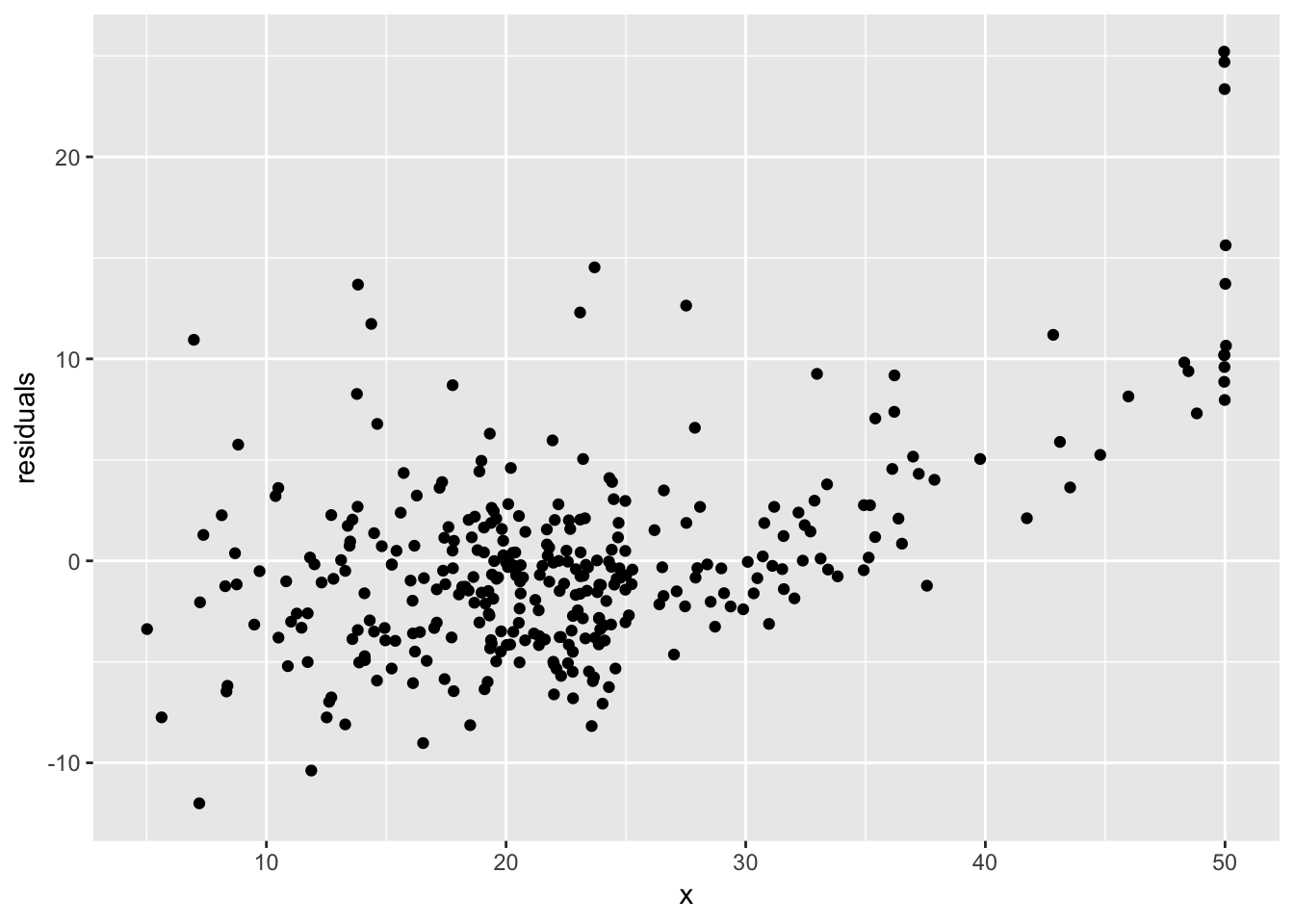
ggplot(df2, aes(x = fitted, y = residuals)) +
geom_jitter()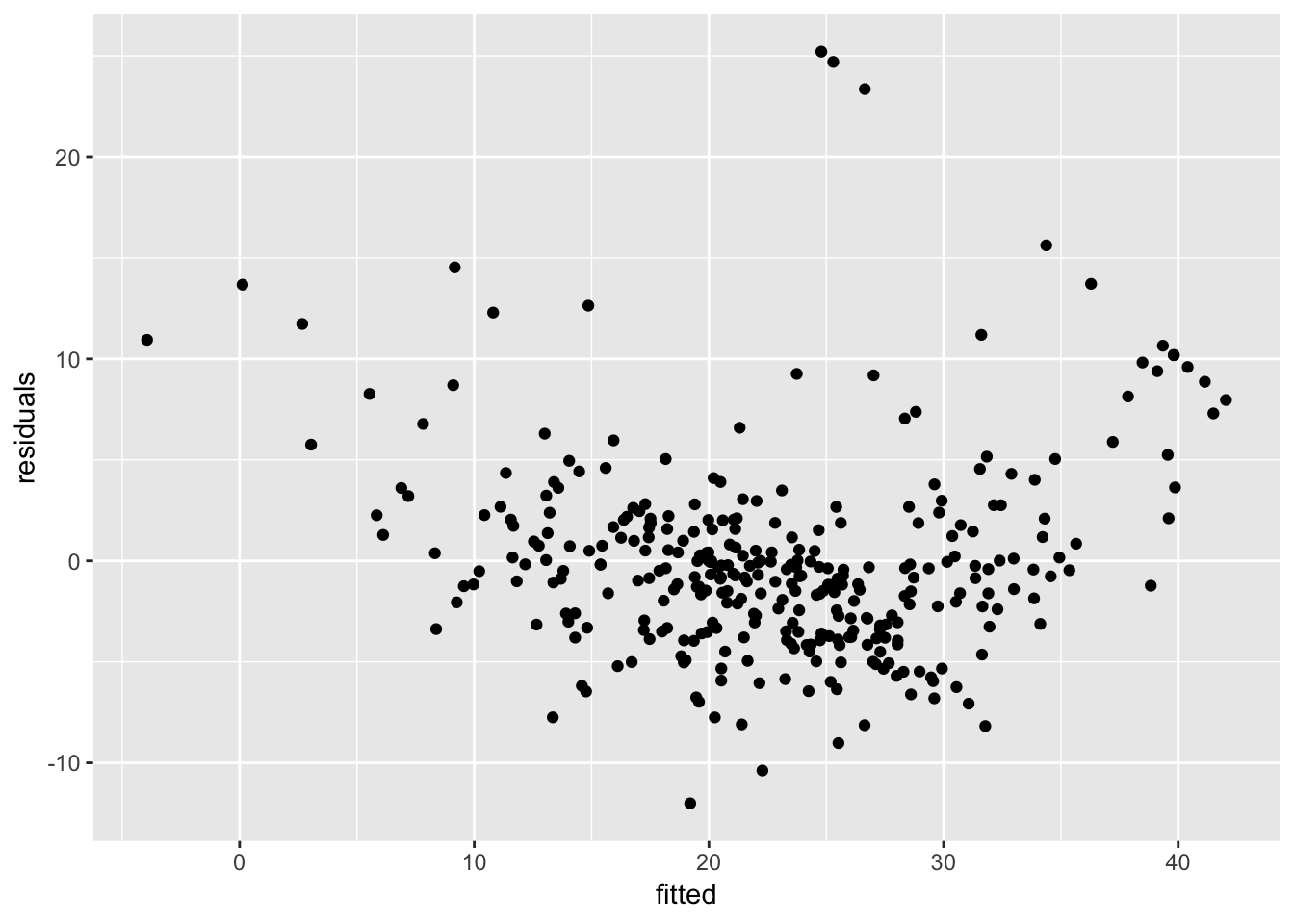
library(ggfortify)
autoplot(model2_mlr_df)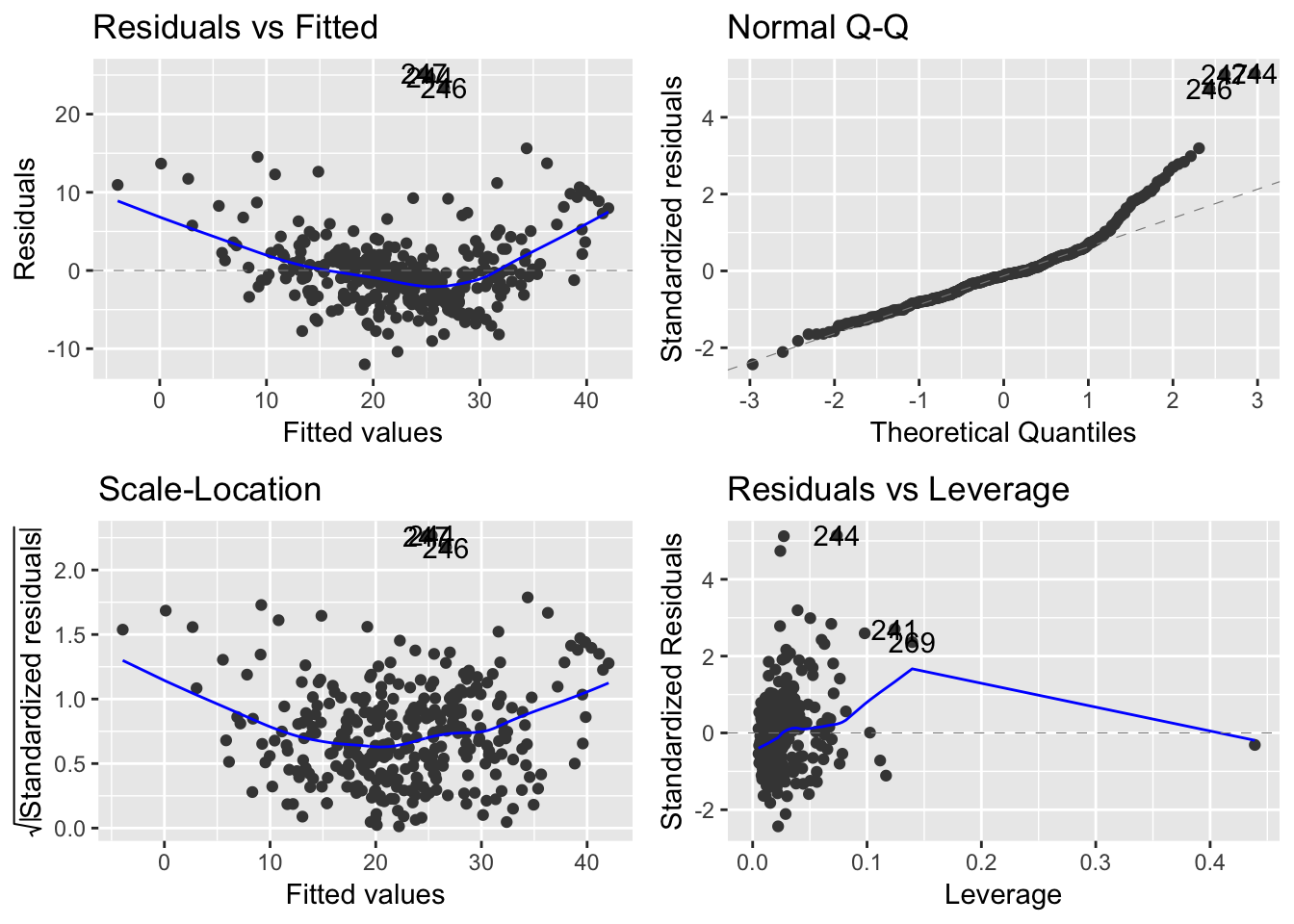
Remember that the error term, \(\epsilon^i\), in the simple linear regression model is independent of x, and is normally distributed, with zero mean and constant variance.↩