Chapter 4 Logistic Regression
4.1 Introduction
Logistic Regression is a classification algorithm. It is used to predict a binary outcome (1 / 0, Yes / No, True / False) given a set of independent variables. To represent binary / categorical outcome, we use dummy variables. You can also think of logistic regression as a special case of linear regression when the outcome variable is categorical, where we are using log of odds as dependent variable. In simple words, it predicts the probability of occurrence of an event by fitting data to a logit function.
Logistic Regression is part of a larger class of algorithms known as Generalized Linear Model (glm).
Although most logisitc regression should be called binomial logistic regression, since the variable to predict is binary, however, logistic regression can also be used to predict a dependent variable which can assume more than 2 values. In this second case we call the model multinomial logistic regression. A typical example for instance, would be classifying films between “Entertaining”, “borderline” or “boring”.
4.2 The logistic equation.
The general equation of the logit model
\[\mathbf{Y} = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + ... + \beta_n x_n\] where Y is the variable to predict.
\(\beta\) is the coefficients of the predictors and the \(x_i\) are the predictors (aka independent variables).
In logistic regression, we are only concerned about the probability of outcome dependent variable ( success or failure). We should then rewrite our function
\[p = e^{(\beta_0 + \beta_1 x_1 + \beta_2 x_2 + ... + \beta_n x_n)}\].
This however does not garantee to have p between 0 and 1.
Let’s then have \[p = \frac{e^{(\beta_0 + \beta_1 x_1 + \beta_2 x_2 + ... + \beta_n x_n)}} {e^{(\beta_0 + \beta_1 x_1 + \beta_2 x_2 + ... + \beta_n x_n)} + 1}\]
or \[p = \frac {e^Y} {e^Y + 1}\]
where p is the probability of success. With little further manipulations, we have \[\frac {p} {1-p} = e^Y\] and \[\log{\frac{p} {1-p}} = Y\]
If we remember what was Y, we get \[\log{\dfrac{p} {1-p}} = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + ... + \beta_n x_n\]
This is the equation used in Logistic Regression. Here (p/1-p) is the odd ratio. Whenever the log of odd ratio is found to be positive, the probability of success is always more than 50%.
4.3 Performance of Logistic Regression Model
To evaluate the performance of a logistic regression model, we can consider a few metrics.
- AIC (Akaike Information Criteria) The analogous metric of adjusted R-squared in logistic regression is AIC. AIC is the measure of fit which penalizes model for the number of model coefficients. Therefore, we always prefer model with minimum AIC value.
- Null Deviance and Residual Deviance Null Deviance indicates the response predicted by a model with nothing but an intercept. Lower the value, better the model. Residual deviance indicates the response predicted by a model on adding independent variables. Lower the value, better the model.
- Confusion Matrix It is nothing but a tabular representation of Actual vs Predicted values. This helps us to find the accuracy of the model and avoid overfitting.
- We can calcualate the accuracy of our model by \[\frac {True Positives + True Negatives}{True Positives + True Negatives + False Positives + False Negatives}\]
- From confusion matrix, Specificity and Sensitivity can be derived as \[Specificity = \frac {True Negatives} {True Negative + False Positive}\] and \[Sensitivity = \frac{True Positive}{True Positive + False Negative}\]
- ROC Curve Receiver Operating Characteristic(ROC) summarizes the model’s performance by evaluating the trade offs between true positive rate (sensitivity) and false positive rate(1- specificity). For plotting ROC, it is advisable to assume p > 0.5 since we are more concerned about success rate. ROC summarizes the predictive power for all possible values of p > 0.5. The area under curve (AUC), referred to as index of accuracy(A) or concordance index, is a perfect performance metric for ROC curve. Higher the area under curve, better the prediction power of the model. The ROC of a perfect predictive model has TP equals 1 and FP equals 0. This curve will touch the top left corner of the graph.
4.4 Setting up
As usual we will use the tidyverse and caret package
library(caret) # For confusion matrix
library(ROCR) # For the ROC curveWe can now get straight to business and see how to model logisitc regression with R and then have the more interesting discussion on its performance.
4.5 Example 1 - Graduate Admission
We use a dataset about factors influencing graduate admission that can be downloaded from the UCLA Institute for Digital Research and Education
The dataset has 4 variables
admitis the response variable
greis the result of a standardized test
gpais the result of the student GPA (school reported)rankis the type of university the student apply for (4 = Ivy League, 1 = lower level entry U.)
Let’s have a quick look at the data and their summary. The goal is to get familiar with the data, type of predictors (continuous, discrete, categorical, etc.)
df <- read_csv("dataset/grad_admission.csv")
glimpse(df)## Observations: 400
## Variables: 4
## $ admit <dbl> 0, 1, 1, 1, 0, 1, 1, 0, 1, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1…
## $ gre <dbl> 380, 660, 800, 640, 520, 760, 560, 400, 540, 700, 800, 440…
## $ gpa <dbl> 3.61, 3.67, 4.00, 3.19, 2.93, 3.00, 2.98, 3.08, 3.39, 3.92…
## $ rank <dbl> 3, 3, 1, 4, 4, 2, 1, 2, 3, 2, 4, 1, 1, 2, 1, 3, 4, 3, 2, 1…#Quick check to see if our response variable is balanced-ish
table(df$admit)##
## 0 1
## 273 127Well that’s not a very balanced response variable, although it is not hugely unbalanced either as it can be the cases sometimes in medical research.
## Two-way contingency table of categorical outcome and predictors
round(prop.table(table(df$admit, df$rank), 2), 2)##
## 1 2 3 4
## 0 0.46 0.64 0.77 0.82
## 1 0.54 0.36 0.23 0.18It seems about right … most students applying to Ivy Leagues graduate programs are not being admitted.
Before we can run our model, let’s transform the rank explanatory variable to a factor.
df2 <- df
df2$rank <- factor(df2$rank)
# Run the model
model_lgr_df2 <- glm(admit ~ ., data = df2, family = "binomial")
summary(model_lgr_df2)##
## Call:
## glm(formula = admit ~ ., family = "binomial", data = df2)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.6268 -0.8662 -0.6388 1.1490 2.0790
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -3.989979 1.139951 -3.500 0.000465 ***
## gre 0.002264 0.001094 2.070 0.038465 *
## gpa 0.804038 0.331819 2.423 0.015388 *
## rank2 -0.675443 0.316490 -2.134 0.032829 *
## rank3 -1.340204 0.345306 -3.881 0.000104 ***
## rank4 -1.551464 0.417832 -3.713 0.000205 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 499.98 on 399 degrees of freedom
## Residual deviance: 458.52 on 394 degrees of freedom
## AIC: 470.52
##
## Number of Fisher Scoring iterations: 4The next part of the output shows the coefficients, their standard errors, the z-statistic (sometimes called a Wald z-statistic), and the associated p-values. Both gre and gpa are statistically significant, as are the three terms for rank. The logistic regression coefficients give the change in the log odds of the outcome for a one unit increase in the predictor variable.
For every one unit change in gre, the log odds of admission (versus non-admission) increases by 0.002.
For a one unit increase in gpa, the log odds of being admitted to graduate school increases by 0.804.
The indicator variables for rank have a slightly different interpretation. For example, having attended an undergraduate institution with rank of 2, versus an institution with a rank of 1, changes the log odds of admission by -0.675.
To see how the variables in the model participates in the decrease of Residual Deviance, we can use the ANOVA function on our model.
anova(model_lgr_df2)## Analysis of Deviance Table
##
## Model: binomial, link: logit
##
## Response: admit
##
## Terms added sequentially (first to last)
##
##
## Df Deviance Resid. Df Resid. Dev
## NULL 399 499.98
## gre 1 13.9204 398 486.06
## gpa 1 5.7122 397 480.34
## rank 3 21.8265 394 458.52We can test for an overall effect of rank (its significance) using the wald.test function of the aod library. The order in which the coefficients are given in the table of coefficients is the same as the order of the terms in the model. This is important because the wald.test function refers to the coefficients by their order in the model. We use the wald.test function. b supplies the coefficients, while Sigma supplies the variance covariance matrix of the error terms, finally Terms tells R which terms in the model are to be tested, in this case, terms 4, 5, and 6, are the three terms for the levels of rank.
library(aod)
wald.test(Sigma = vcov(model_lgr_df2), b = coef(model_lgr_df2), Terms = 4:6)## Wald test:
## ----------
##
## Chi-squared test:
## X2 = 20.9, df = 3, P(> X2) = 0.00011The chi-squared test statistic of 20.9, with three degrees of freedom is associated with a p-value of 0.00011 indicating that the overall effect of rank is statistically significant.
Let’s check how our model is performing. As mentioned earlier, we need to make a choice on the cutoff value (returned probability) to check our accuracy. In this first example, let’s just stick with the usual 0.5 cutoff value.
prediction_lgr_df2 <- predict(model_lgr_df2, data = df2, type = "response")
head(prediction_lgr_df2, 10)## 1 2 3 4 5 6 7
## 0.1726265 0.2921750 0.7384082 0.1783846 0.1183539 0.3699699 0.4192462
## 8 9 10
## 0.2170033 0.2007352 0.5178682As it stands, the predict function gives us the probabilty that the observation has a response of 1; in our case, the probability that a student is being admitted into the graduate program.
To check the accuracy of the model, we need a confusion matrix with a cut off value. So let’s clean that vector of probability.
prediction_lgr_df2 <- if_else(prediction_lgr_df2 > 0.5 , 1, 0)
confusionMatrix(data = factor(prediction_lgr_df2),
reference = factor(df2$admit), positive = "1")## Confusion Matrix and Statistics
##
## Reference
## Prediction 0 1
## 0 254 97
## 1 19 30
##
## Accuracy : 0.71
## 95% CI : (0.6628, 0.754)
## No Information Rate : 0.6825
## P-Value [Acc > NIR] : 0.1293
##
## Kappa : 0.1994
## Mcnemar's Test P-Value : 8.724e-13
##
## Sensitivity : 0.2362
## Specificity : 0.9304
## Pos Pred Value : 0.6122
## Neg Pred Value : 0.7236
## Prevalence : 0.3175
## Detection Rate : 0.0750
## Detection Prevalence : 0.1225
## Balanced Accuracy : 0.5833
##
## 'Positive' Class : 1
## We have an interesting situation here. Although all our variables were significant in our model, the accuracy of our model, 71% is just a little bit higher than the basic benchmark which is the no-information model (ie. we just predict the highest class) in this case 68.25%.
Before we do a ROC curve, let’s have a quick reminder on ROC.
ROC are plotting the proprotion of TP to FP. So ideally we want to have 100% TP and 0% FP.
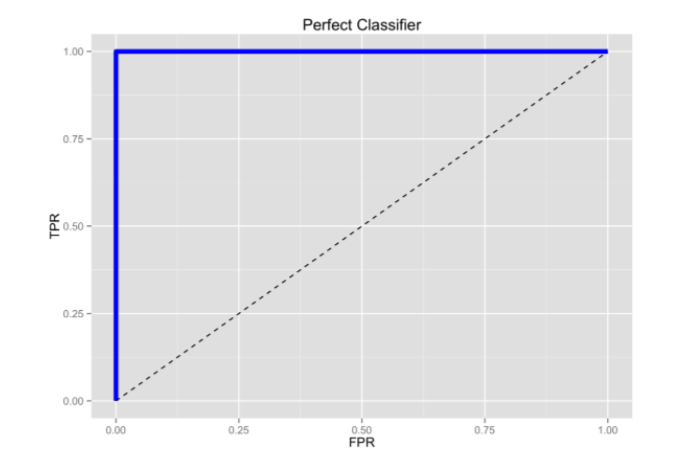
Pure Random guessing should lead to this curve
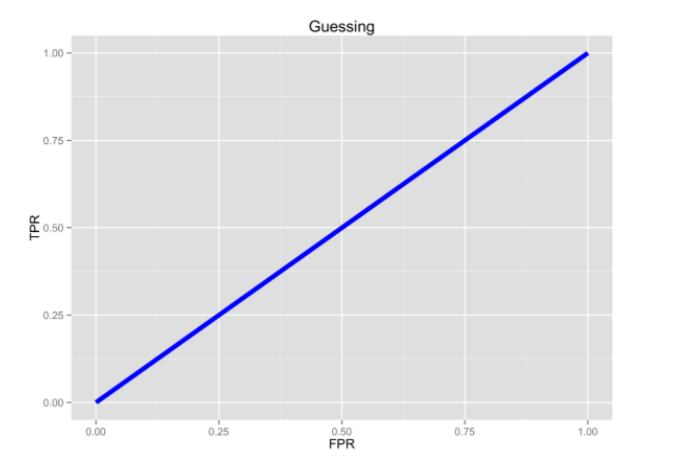
With that in mind, let’s do a ROC curve on out model
prediction_lgr_df2 <- predict(model_lgr_df2, data = df2, type="response")
pr_admission <- prediction(prediction_lgr_df2, df2$admit)
prf_admission <- performance(pr_admission, measure = "tpr", x.measure = "fpr")
plot(prf_admission, colorize = TRUE, lwd=3)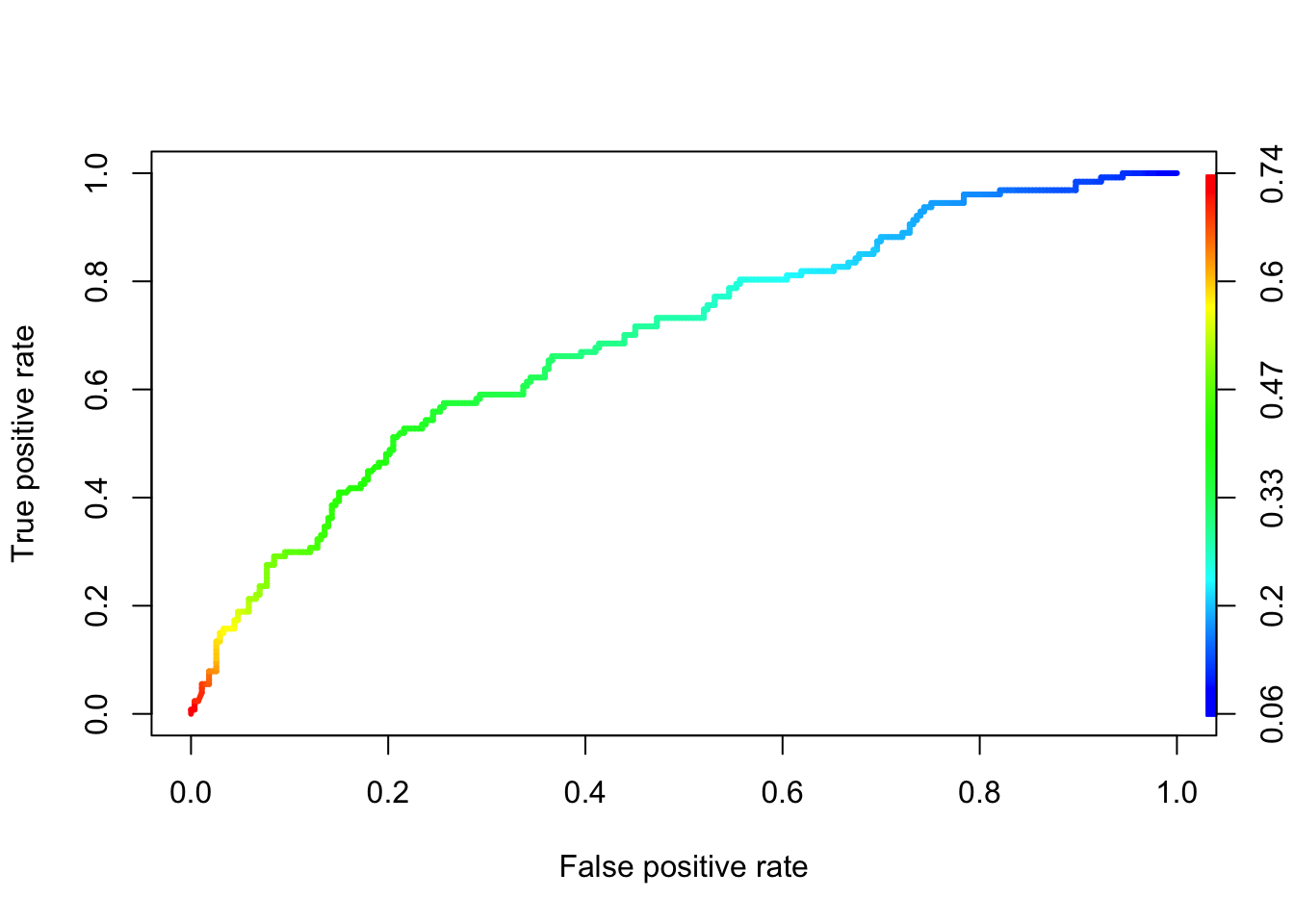
At least it is better than just random guessing.
In some applications of ROC curves, you want the point closest to the TPR of \(1\) and FPR of \(0\). This cut point is “optimal” in the sense it weighs both sensitivity and specificity equally. Now, there is a cost measure in the ROCR package that you can use to create a performance object. Use it to find the cutoff with minimum cost.
cost_admission_perf = performance(pr_admission, "cost")
cutoff <- pr_admission@cutoffs[[1]][which.min(cost_admission_perf@y.values[[1]])]Using that cutoff value we should get our sensitivity and specificity a bit more in balance. Let’s try
prediction_lgr_df2 <- predict(model_lgr_df2, data = df2, type = "response")
prediction_lgr_df2 <- if_else(prediction_lgr_df2 > cutoff , 1, 0)
confusionMatrix(data = factor(prediction_lgr_df2),
reference = factor(df2$admit),
positive = "1")## Confusion Matrix and Statistics
##
## Reference
## Prediction 0 1
## 0 250 91
## 1 23 36
##
## Accuracy : 0.715
## 95% CI : (0.668, 0.7588)
## No Information Rate : 0.6825
## P-Value [Acc > NIR] : 0.08878
##
## Kappa : 0.2325
## Mcnemar's Test P-Value : 3.494e-10
##
## Sensitivity : 0.2835
## Specificity : 0.9158
## Pos Pred Value : 0.6102
## Neg Pred Value : 0.7331
## Prevalence : 0.3175
## Detection Rate : 0.0900
## Detection Prevalence : 0.1475
## Balanced Accuracy : 0.5996
##
## 'Positive' Class : 1
## And bonus, we even gained some accuracy!
I have seen a very cool graph on this website that plots this tradeoff between specificity and sensitivity and shows how this cutoff point can enhance the understanding of the predictive power of our model.
# Create tibble with both prediction and actual value
cutoff = 0.487194
cutoff_plot <- tibble(predicted = predict(model_lgr_df2, data = df2, type = "response"),
actual = as.factor(df2$admit)) %>%
mutate(type = if_else(predicted >= cutoff & actual == 1, "TP",
if_else(predicted >= cutoff & actual == 0, "FP",
if_else(predicted < cutoff & actual == 0, "TN", "FN"))))
cutoff_plot$type <- as.factor(cutoff_plot$type)
ggplot(cutoff_plot, aes(x = actual, y = predicted, color = type)) +
geom_violin(fill = "white", color = NA) +
geom_jitter(shape = 1) +
geom_hline(yintercept = cutoff, color = "blue", alpha = 0.5) +
scale_y_continuous(limits = c(0, 1)) +
ggtitle(paste0("Confusion Matrix with cutoff at ", cutoff))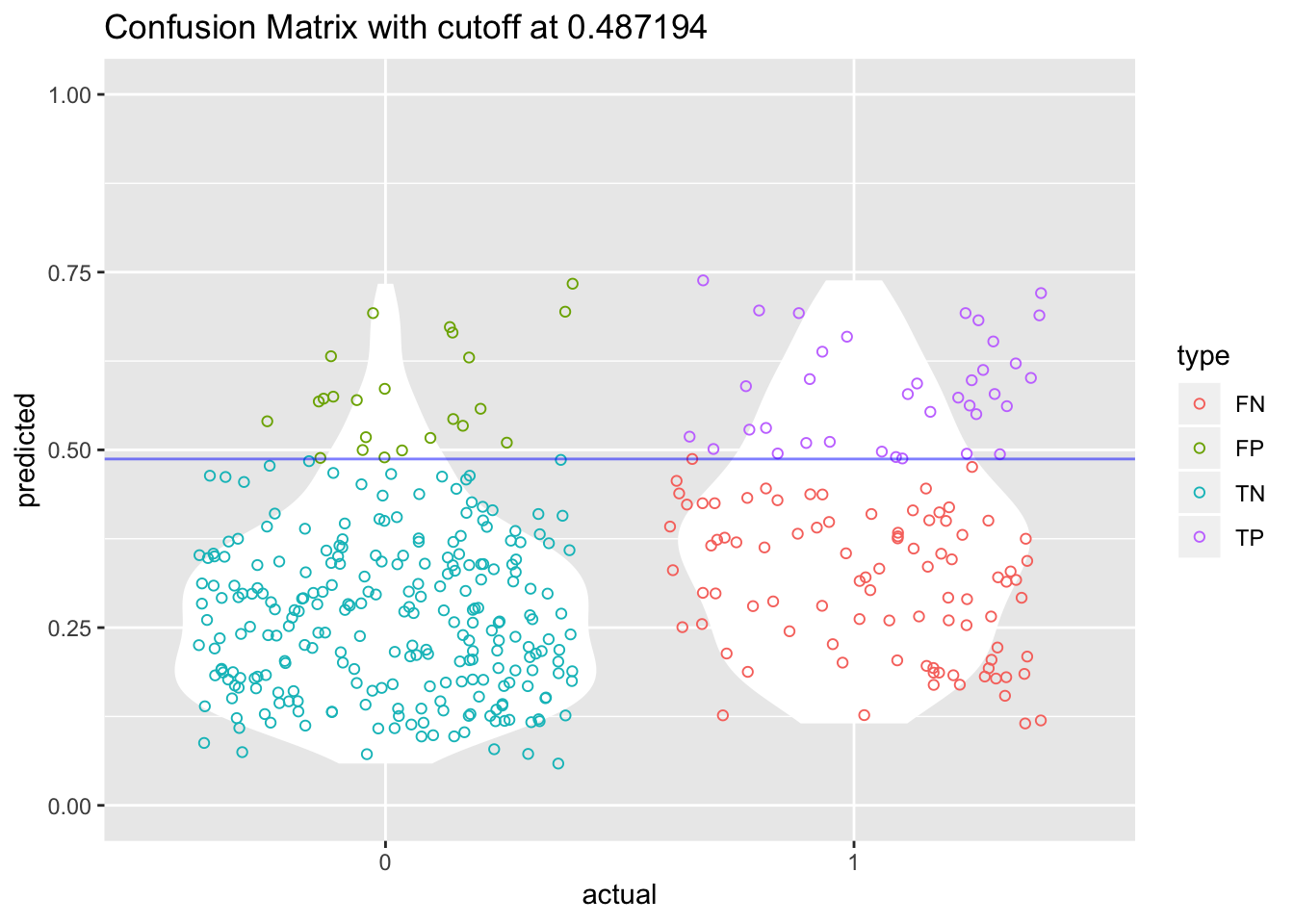
Last thing … the AUC, aka Area Under the Curve.
The AUC is basically the area under the ROC curve.
You can think of the AUC as sort of a holistic number that represents how well your TP and FP is looking in aggregate.
AUC=0.5 -> BAD
AUC=1 -> GOOD 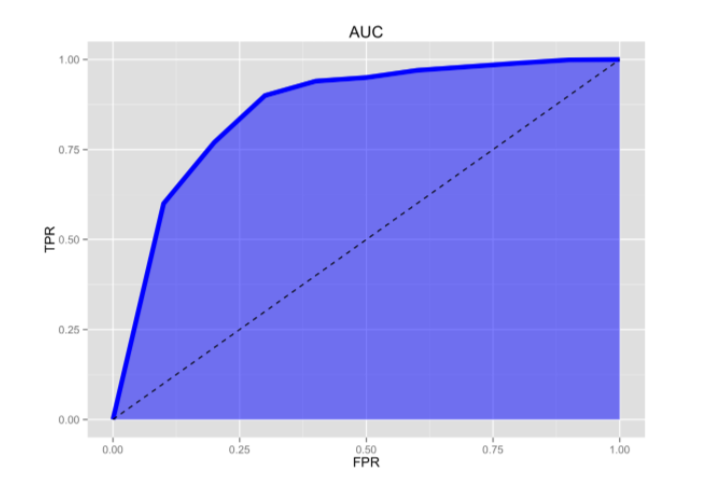
So in the context of an ROC curve, the more “up and left” it looks, the larger the AUC will be and thus, the better your classifier is. Comparing AUC values is also really useful when comparing different models, as we can select the model with the high AUC value, rather than just look at the curves.
In our situation with our model model_admission_lr, we can find our AUC with the ROCR package.
prediction_lgr_df2 <- predict(model_lgr_df2, data = df2, type="response")
pr_admission <- prediction(prediction_lgr_df2, df2$admit)
auc_admission <- performance(pr_admission, measure = "auc")
# and to get the exact value
auc_admission@y.values[[1]]## [1] 0.69284134.6 Example 2 - Diabetes
In our second example we will use the Pima Indians Diabetes Data Set that can be downloaded on the UCI Machine learning website.
We are also dropping a clean version of the file as .csv on our github dataset folder.
The data set records females patients of at least 21 years old of Pima Indian heritage.
df <- read_csv("dataset/diabetes.csv")The dataset has 768 observations and 9 variables.
Let’s rename our variables with the proper names.
colnames(df) <- c("pregnant", "glucose", "diastolic",
"triceps", "insulin", "bmi", "diabetes", "age",
"test")
glimpse(df)## Observations: 768
## Variables: 9
## $ pregnant <dbl> 6, 1, 8, 1, 0, 5, 3, 10, 2, 8, 4, 10, 10, 1, 5, 7, 0, …
## $ glucose <dbl> 148, 85, 183, 89, 137, 116, 78, 115, 197, 125, 110, 16…
## $ diastolic <dbl> 72, 66, 64, 66, 40, 74, 50, 0, 70, 96, 92, 74, 80, 60,…
## $ triceps <dbl> 35, 29, 0, 23, 35, 0, 32, 0, 45, 0, 0, 0, 0, 23, 19, 0…
## $ insulin <dbl> 0, 0, 0, 94, 168, 0, 88, 0, 543, 0, 0, 0, 0, 846, 175,…
## $ bmi <dbl> 33.6, 26.6, 23.3, 28.1, 43.1, 25.6, 31.0, 35.3, 30.5, …
## $ diabetes <dbl> 0.627, 0.351, 0.672, 0.167, 2.288, 0.201, 0.248, 0.134…
## $ age <dbl> 50, 31, 32, 21, 33, 30, 26, 29, 53, 54, 30, 34, 57, 59…
## $ test <dbl> 1, 0, 1, 0, 1, 0, 1, 0, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, …All variables seems to have been recorded with the appropriate type in the data frame. Let’s just change the type of the response variable to factor with positive and negative levels.
df$test <- factor(df$test)
#levels(df$output) <- c("negative", "positive")Let’s do our regression on the whole dataset.
df2 <- df
model_lgr_df2 <- glm(test ~., data = df2, family = "binomial")
summary(model_lgr_df2)##
## Call:
## glm(formula = test ~ ., family = "binomial", data = df2)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -2.5566 -0.7274 -0.4159 0.7267 2.9297
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -8.4046964 0.7166359 -11.728 < 2e-16 ***
## pregnant 0.1231823 0.0320776 3.840 0.000123 ***
## glucose 0.0351637 0.0037087 9.481 < 2e-16 ***
## diastolic -0.0132955 0.0052336 -2.540 0.011072 *
## triceps 0.0006190 0.0068994 0.090 0.928515
## insulin -0.0011917 0.0009012 -1.322 0.186065
## bmi 0.0897010 0.0150876 5.945 2.76e-09 ***
## diabetes 0.9451797 0.2991475 3.160 0.001580 **
## age 0.0148690 0.0093348 1.593 0.111192
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 993.48 on 767 degrees of freedom
## Residual deviance: 723.45 on 759 degrees of freedom
## AIC: 741.45
##
## Number of Fisher Scoring iterations: 5If we look at the z-statistic and the associated p-values, we can see that the variables triceps, insulin and age are not significant variables.
The logistic regression coefficients give the change in the log odds of the outcome for a one unit increase in the predictor variable. Hence, everything else being equals, any additional pregnancy increase the log odds of having diabetes (class_variable = 1) by another 0.1231.
We can see the confidence interval for each variables using the confint function.
confint(model_lgr_df2)## Waiting for profiling to be done...## 2.5 % 97.5 %
## (Intercept) -9.860319374 -7.0481062619
## pregnant 0.060918463 0.1868558244
## glucose 0.028092756 0.0426500736
## diastolic -0.023682464 -0.0031039754
## triceps -0.012849460 0.0142115759
## insulin -0.002966884 0.0005821426
## bmi 0.060849478 0.1200608498
## diabetes 0.365370025 1.5386561742
## age -0.003503266 0.0331865712If we want to get the odds, we basically exponentiate the coefficients.
exp(coef(model_lgr_df2))## (Intercept) pregnant glucose diastolic triceps
## 0.0002238137 1.1310905981 1.0357892688 0.9867924485 1.0006191560
## insulin bmi diabetes age
## 0.9988090108 1.0938471417 2.5732758592 1.0149800983In this way, for every additional year of age, the odds of getting diabetes (test = positive) is increasing by 1.015.
Let’s have a first look at how our model perform
prediction_lgr_df2 <- predict(model_lgr_df2, data = df2, type="response")
prediction_lgr_df2 <- if_else(prediction_lgr_df2 > 0.5, 1, 0)
#prediction_diabetes_lr <- factor(prediction_diabetes_lr)
#levels(prediction_diabetes_lr) <- c("negative", "positive")
table(df2$test)##
## 0 1
## 500 268confusionMatrix(data = factor(prediction_lgr_df2),
reference = factor(df2$test),
positive = "1")## Confusion Matrix and Statistics
##
## Reference
## Prediction 0 1
## 0 445 112
## 1 55 156
##
## Accuracy : 0.7826
## 95% CI : (0.7517, 0.8112)
## No Information Rate : 0.651
## P-Value [Acc > NIR] : 1.373e-15
##
## Kappa : 0.4966
## Mcnemar's Test P-Value : 1.468e-05
##
## Sensitivity : 0.5821
## Specificity : 0.8900
## Pos Pred Value : 0.7393
## Neg Pred Value : 0.7989
## Prevalence : 0.3490
## Detection Rate : 0.2031
## Detection Prevalence : 0.2747
## Balanced Accuracy : 0.7360
##
## 'Positive' Class : 1
## Let’s create our ROC curve
prediction_lgr_df2 <- predict(model_lgr_df2, data = df2, type="response")
pr_diabetes <- prediction(prediction_lgr_df2, df2$test)
prf_diabetes <- performance(pr_diabetes, measure = "tpr", x.measure = "fpr")
plot(prf_diabetes, colorize = TRUE, lwd = 3)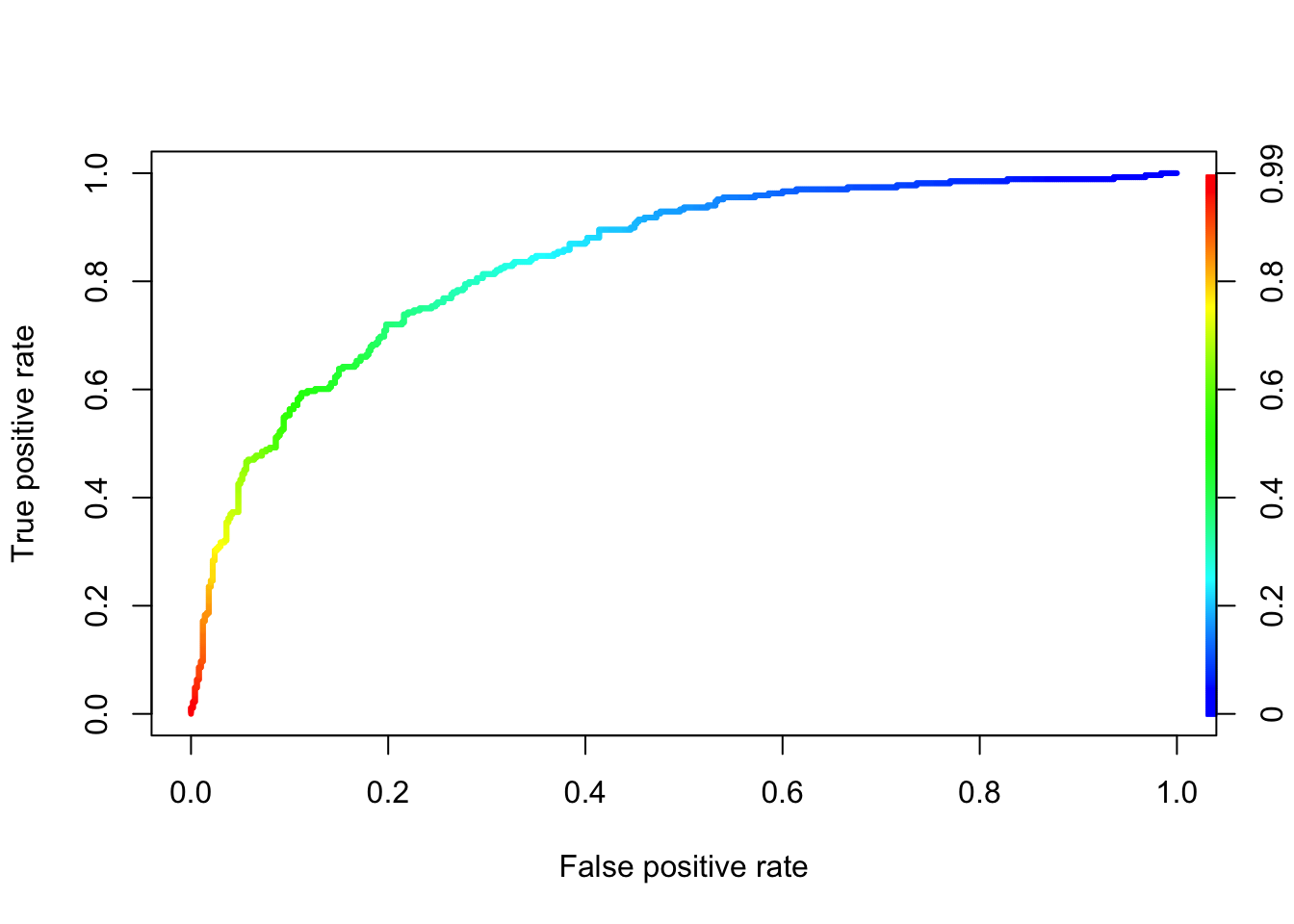
Let’s find the best cutoff value for our model.
cost_diabetes_perf = performance(pr_diabetes, "cost")
cutoff <- pr_diabetes@cutoffs[[1]][which.min(cost_diabetes_perf@y.values[[1]])]Instead of redoing the whole violin-jitter graph for our model, let’s create a function so we can reuse it at a later stage.
violin_jitter_graph <- function(cutoff, df_predicted, df_actual){
cutoff_tibble <- tibble(predicted = df_predicted, actual = as.factor(df_actual)) %>%
mutate(type = if_else(predicted >= cutoff & actual == 1, "TP",
if_else(predicted >= cutoff & actual == 0, "FP",
if_else(predicted < cutoff & actual == 0, "TN", "FN"))))
cutoff_tibble$type <- as.factor(cutoff_tibble$type)
ggplot(cutoff_tibble, aes(x = actual, y = predicted, color = type)) +
geom_violin(fill = "white", color = NA) +
geom_jitter(shape = 1) +
geom_hline(yintercept = cutoff, color = "blue", alpha = 0.5) +
scale_y_continuous(limits = c(0, 1)) +
ggtitle(paste0("Confusion Matrix with cutoff at ", cutoff))
}
violin_jitter_graph(cutoff, predict(model_lgr_df2, data = df2, type = "response"), df2$test)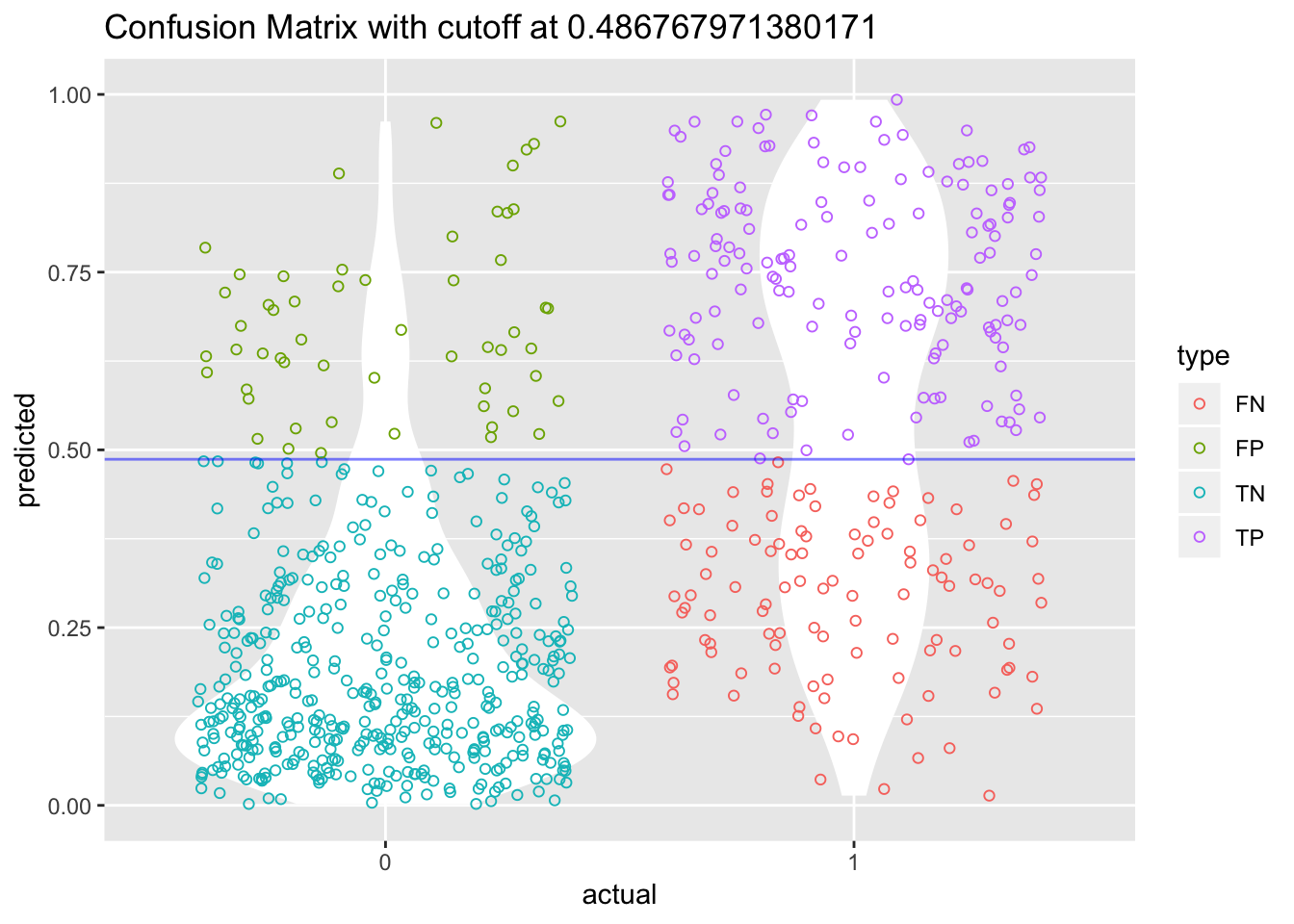
The accuracy of our model is slightly improved by using that new cutoff value.
4.6.1 Accounting for missing values
The UCI Machine Learning website note that there are no missing values on this dataset. That said, we have to be careful as there are many 0, when it is actually impossible to have such 0.
So before we keep going let’s fill in these values.
The first thing to to is to change these 0 into NA.
df3 <- df2
#TODO Find a way to create a function and use map from purrr to do this
df3$glucose[df3$glucose == 0] <- NA
df3$diastolic[df3$diastolic == 0] <- NA
df3$triceps[df3$triceps == 0] <- NA
df3$insulin[df3$insulin == 0] <- NA
df3$bmi[df3$bmi == 0] <- NAlibrary(visdat)
vis_dat(df3)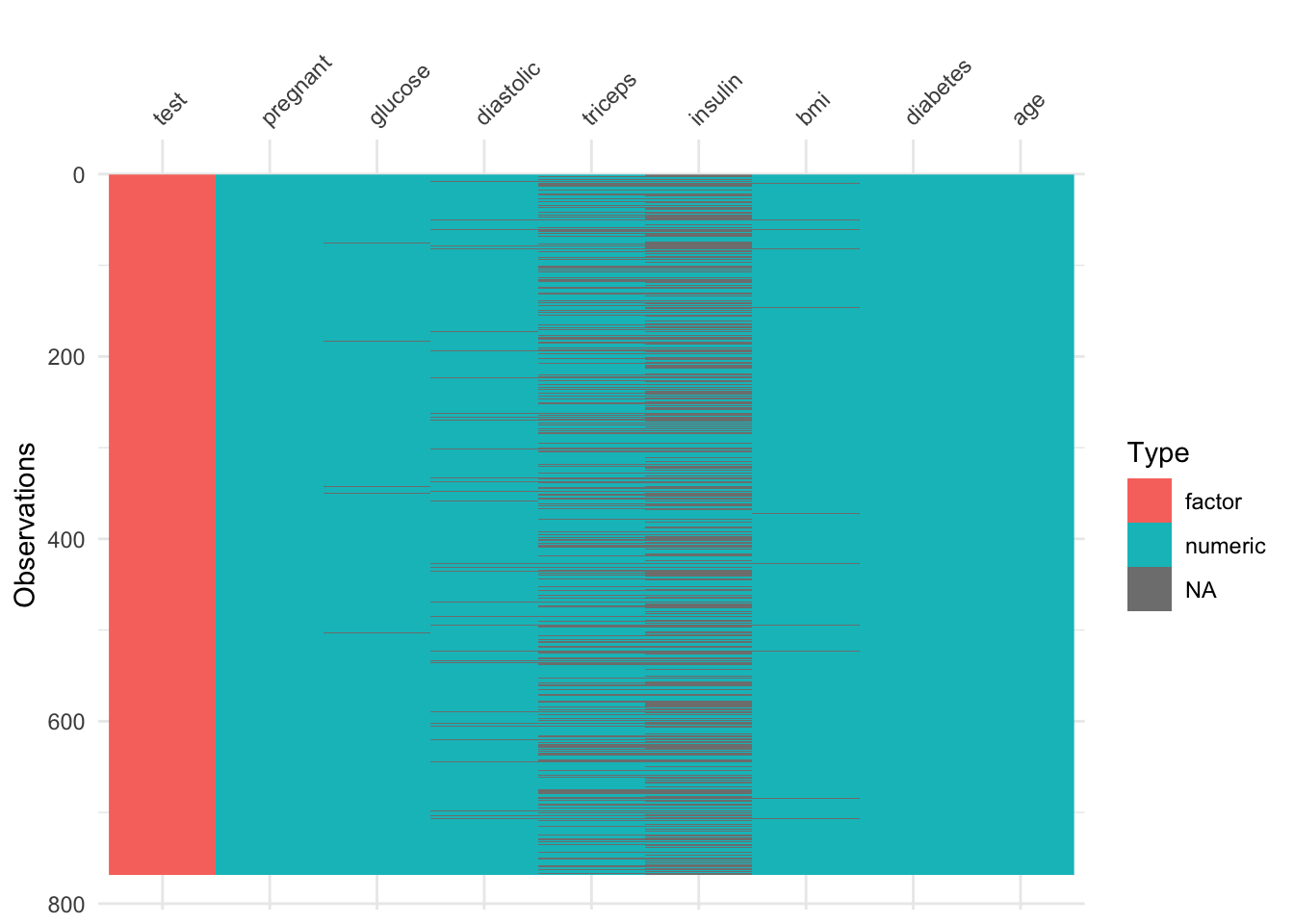
There are a lot of missing values … too many of them really. If this was really life, it would be important to go back to the drawing board and redisigning the data collection phase.
model_lgr_df3 <- glm(test ~., data = df3, family = "binomial")
summary(model_lgr_df3)##
## Call:
## glm(formula = test ~ ., family = "binomial", data = df3)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -2.7823 -0.6603 -0.3642 0.6409 2.5612
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -1.004e+01 1.218e+00 -8.246 < 2e-16 ***
## pregnant 8.216e-02 5.543e-02 1.482 0.13825
## glucose 3.827e-02 5.768e-03 6.635 3.24e-11 ***
## diastolic -1.420e-03 1.183e-02 -0.120 0.90446
## triceps 1.122e-02 1.708e-02 0.657 0.51128
## insulin -8.253e-04 1.306e-03 -0.632 0.52757
## bmi 7.054e-02 2.734e-02 2.580 0.00989 **
## diabetes 1.141e+00 4.274e-01 2.669 0.00760 **
## age 3.395e-02 1.838e-02 1.847 0.06474 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 498.10 on 391 degrees of freedom
## Residual deviance: 344.02 on 383 degrees of freedom
## (376 observations deleted due to missingness)
## AIC: 362.02
##
## Number of Fisher Scoring iterations: 5This leads to a very different results than previously.
Let’s have a look at this new model performance
prediction_lgr_df3 <- predict(model_lgr_df3, data = df3, type="response")
prediction_lgr_df3 <- if_else(prediction_lgr_df3 > 0.5, 1, 0)
#prediction_diabetes_lr <- factor(prediction_diabetes_lr)
#levels(prediction_diabetes_lr) <- c("negative", "positive")
table(df3$test)##
## 0 1
## 500 268#confusionMatrix(data = prediction_diabetes_lr2,
# reference = df2$test,
# positive = "1")4.6.2 Imputting Missing Values
Now let’s impute the missing values using the simputatiion package. A nice vignette is available here.
library(simputation)
df4 <- df3
df4 <- impute_lm(df3, formula = glucose ~ pregnant + diabetes + age | test)
df4 <- impute_rf(df4, formula = bmi ~ glucose + pregnant + diabetes + age | test)
df4 <- impute_rf(df4, formula = diastolic ~ bmi + glucose + pregnant + diabetes + age | test)
df4 <- impute_en(df4, formula = triceps ~ pregnant + bmi + diabetes + age | test)
df4 <- impute_rf(df4, formula = insulin ~ . | test)
summary(df4)## pregnant glucose diastolic triceps
## Min. : 0.000 Min. : 44.00 Min. : 24.00 Min. : 7.0
## 1st Qu.: 1.000 1st Qu.: 99.75 1st Qu.: 64.00 1st Qu.:22.0
## Median : 3.000 Median :117.00 Median : 72.00 Median :29.0
## Mean : 3.845 Mean :121.68 Mean : 72.36 Mean :28.9
## 3rd Qu.: 6.000 3rd Qu.:141.00 3rd Qu.: 80.00 3rd Qu.:35.0
## Max. :17.000 Max. :199.00 Max. :122.00 Max. :99.0
## insulin bmi diabetes age test
## Min. : 14.00 Min. :18.20 Min. :0.0780 Min. :21.00 0:500
## 1st Qu.: 92.73 1st Qu.:27.50 1st Qu.:0.2437 1st Qu.:24.00 1:268
## Median :138.45 Median :32.21 Median :0.3725 Median :29.00
## Mean :155.91 Mean :32.43 Mean :0.4719 Mean :33.24
## 3rd Qu.:192.20 3rd Qu.:36.60 3rd Qu.:0.6262 3rd Qu.:41.00
## Max. :846.00 Max. :67.10 Max. :2.4200 Max. :81.00Ok we managed to get rid of the NAs. Let’s run a last time our logistic model.
model_lgr_df4 <- glm(test ~ ., data = df4, family = "binomial")
summary(model_lgr_df4)##
## Call:
## glm(formula = test ~ ., family = "binomial", data = df4)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -3.3142 -0.6993 -0.3864 0.7203 2.3773
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -8.639981 0.821457 -10.518 < 2e-16 ***
## pregnant 0.127325 0.032244 3.949 7.85e-05 ***
## glucose 0.030705 0.004143 7.411 1.26e-13 ***
## diastolic -0.006882 0.008691 -0.792 0.42846
## triceps 0.004442 0.014450 0.307 0.75855
## insulin 0.003536 0.001344 2.631 0.00851 **
## bmi 0.081455 0.020825 3.911 9.17e-05 ***
## diabetes 0.838278 0.298054 2.812 0.00492 **
## age 0.009847 0.009698 1.015 0.30991
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 993.48 on 767 degrees of freedom
## Residual deviance: 704.27 on 759 degrees of freedom
## AIC: 722.27
##
## Number of Fisher Scoring iterations: 5prediction_lgr_df4 <- predict(model_lgr_df4, data = df4, type="response")
prediction_lgr_df4 <- if_else(prediction_lgr_df4 > 0.5, "positive", "negative")
prediction_lgr_df4 <- factor(prediction_lgr_df4)
levels(prediction_lgr_df4) <- c("negative", "positive")
#table(df4$test, prediction_lgr_df4)
#table(df4$test)
########
#confusionMatrix(data = accuracy_model_lr3,
# reference = df3$test,
# positive = "positive")4.6.3 ROC and AUC
prediction_lgr_df4 <- predict(model_lgr_df4, data = df4, type="response")
#pr <- prediction(prediction_lgr_df4, df4$test)
#prf <- performance(pr, measure = "tpr", x.measure = "fpr")
#plot(prf)Let’s go back to the ideal cut off point that would balance the sensitivity and specificity.
#cost_diabetes_perf <- performance(pr, "cost")
#cutoff <- pr@cutoffs[[1]][which.min(cost_diabetes_perf@y.values[[1]])]So for maximum accuracy, the ideal cutoff point is 0.487194.
Let’s redo our confusion matrix then and see some improvement.
prediction_lgr_df4 <- predict(model_lgr_df4, data = df4, type="response")
prediction_lgr_df4 <- if_else(prediction_lgr_df4 >= cutoff, "positive", "negative")
#confusionMatrix(data = accuracy_model_lr3,
# reference = df3$test,
# positive = "positive")Another cost measure that is popular is overall accuracy. This measure optimizes the correct results, but may be skewed if there are many more negatives than positives, or vice versa. Let’s get the overall accuracy for the simple predictions and plot it.
Actually the ROCR package can also give us a plot of accuracy for various cutoff points
#prediction_lgr_df4 <- performance(pr, measure = "acc")
#plot(prediction_lgr_df4)Often in medical research for instance, there is a cost in having false negative is quite higher than a false positve.
Let’s say the cost of missing someone having diabetes is 3 times the cost of telling someone that he has diabetes when in reality he/she doesn’t.
#cost_diabetes_perf <- performance(pr, "cost", cost.fp = 1, cost.fn = 3)
#cutoff <- pr@cutoffs[[1]][which.min(cost_diabetes_perf@y.values[[1]])]Lastly, in regards to AUC
#auc <- performance(pr, measure = "auc")
#auc <- auc@y.values[[1]]
#auc4.7 References
The Introduction is from the AV website
The UCLA Institute for Digital Research and Education site where we got the dataset for our first example
- The UCI Machine learning site where we got the dataset for our second example
Function to use ROC with ggplot2 - The Joy of Data and here as well