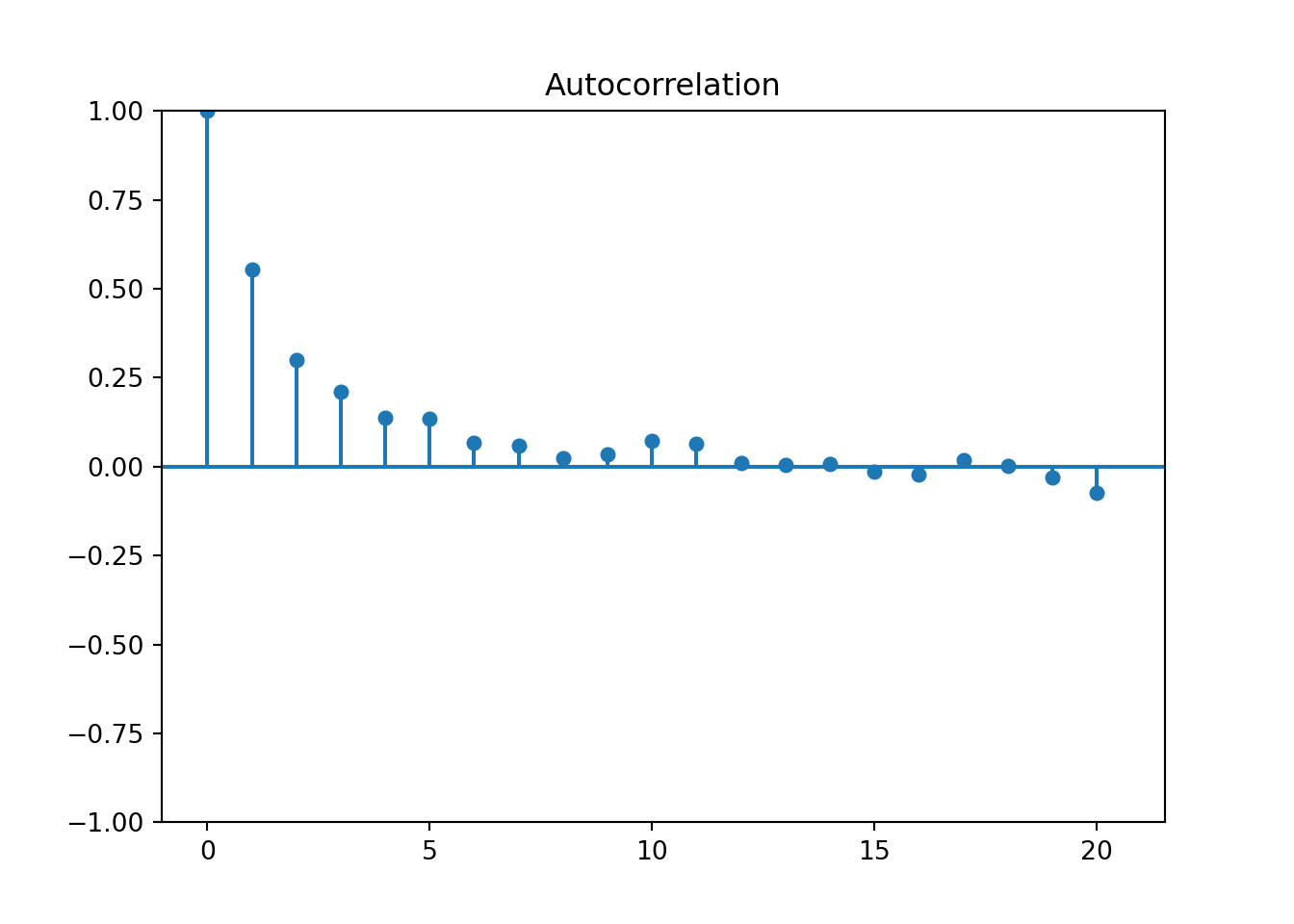
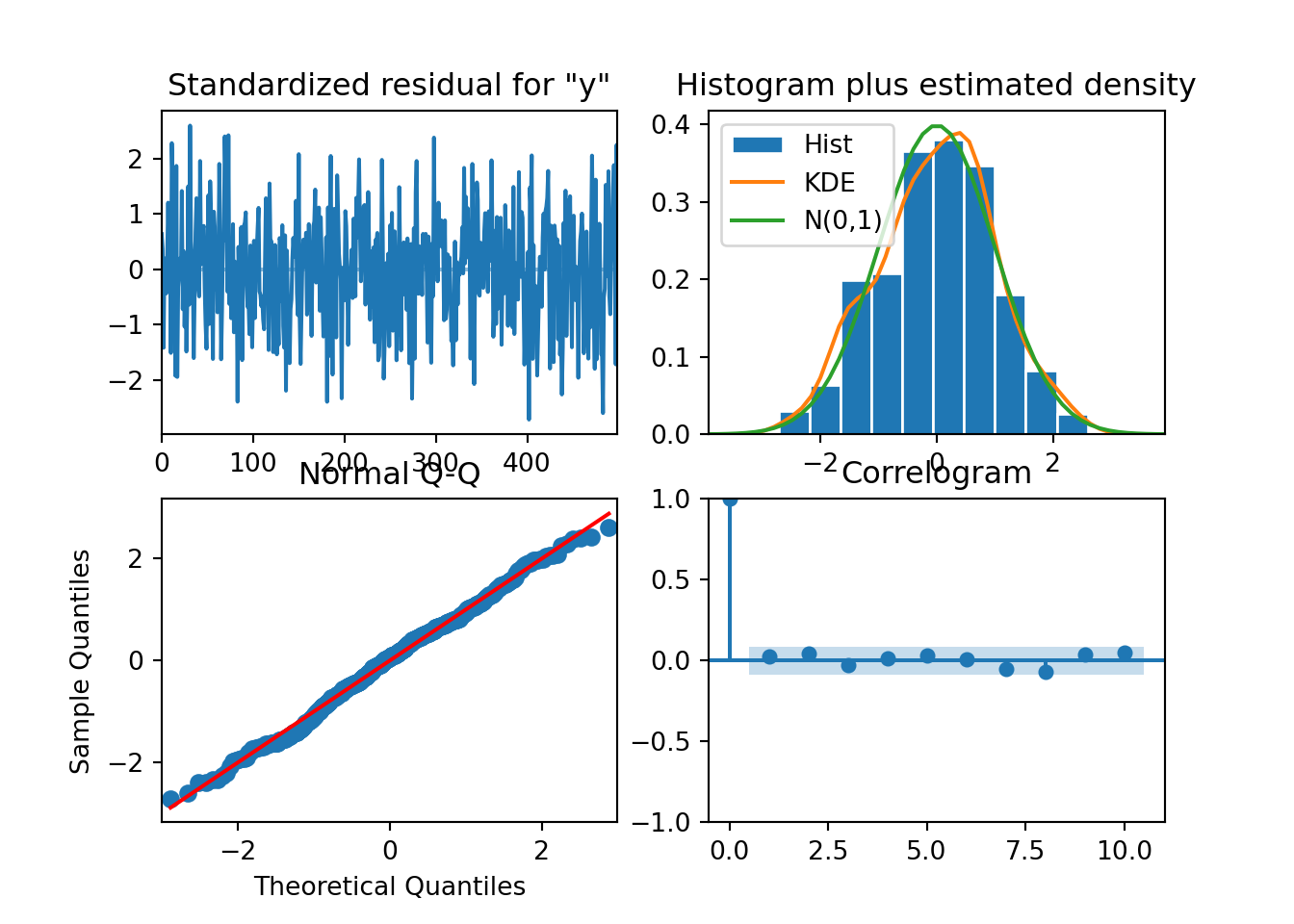
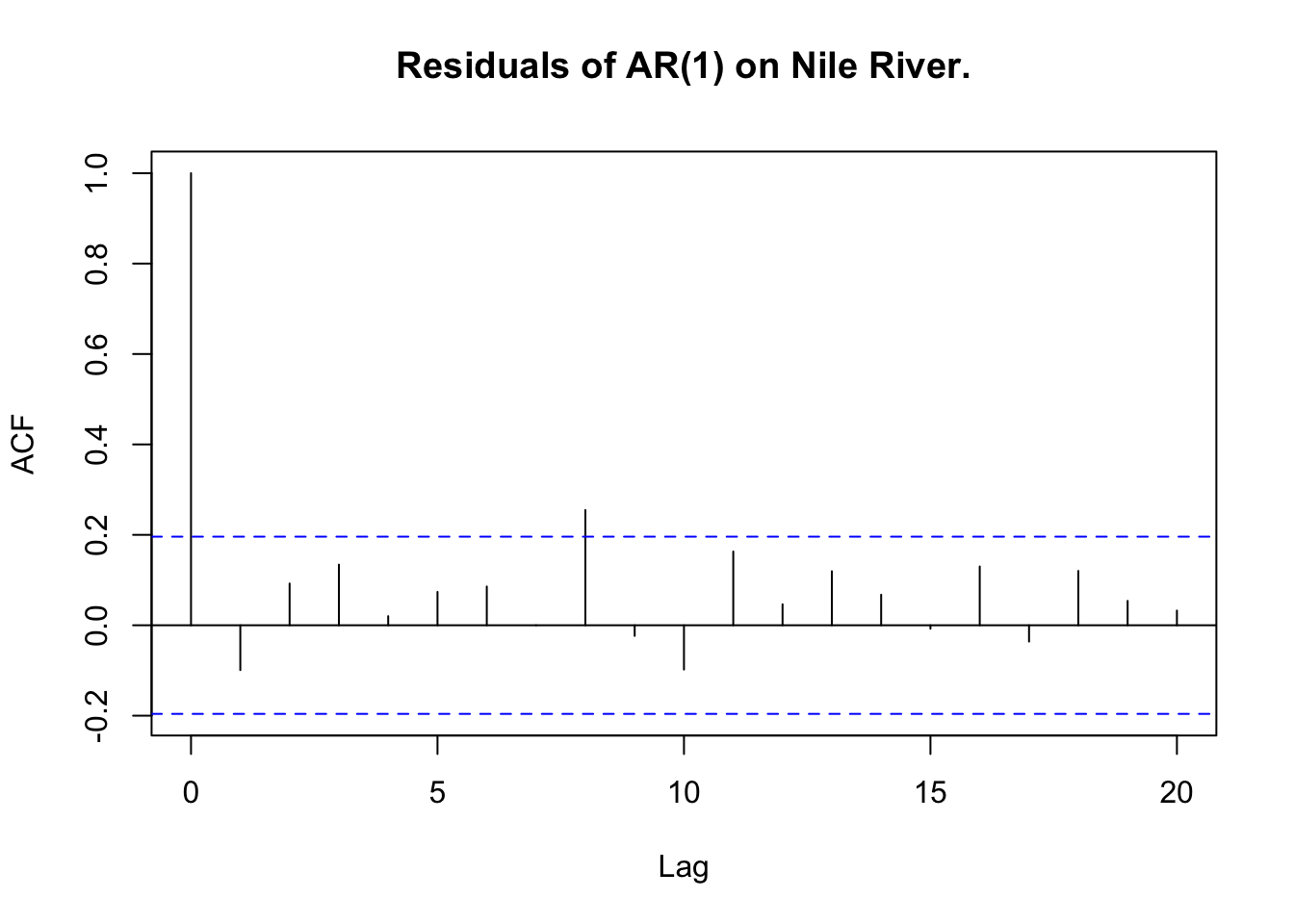
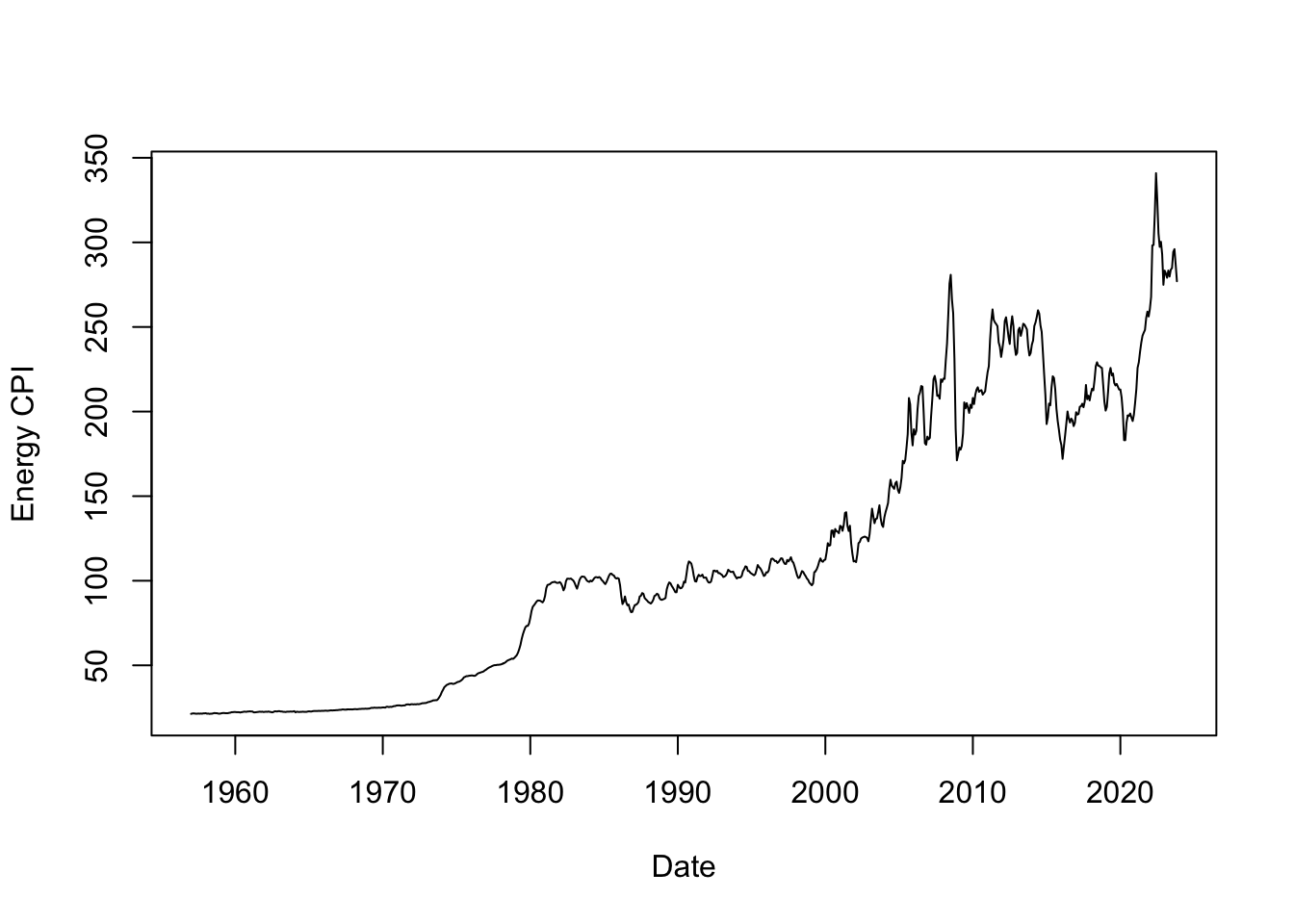
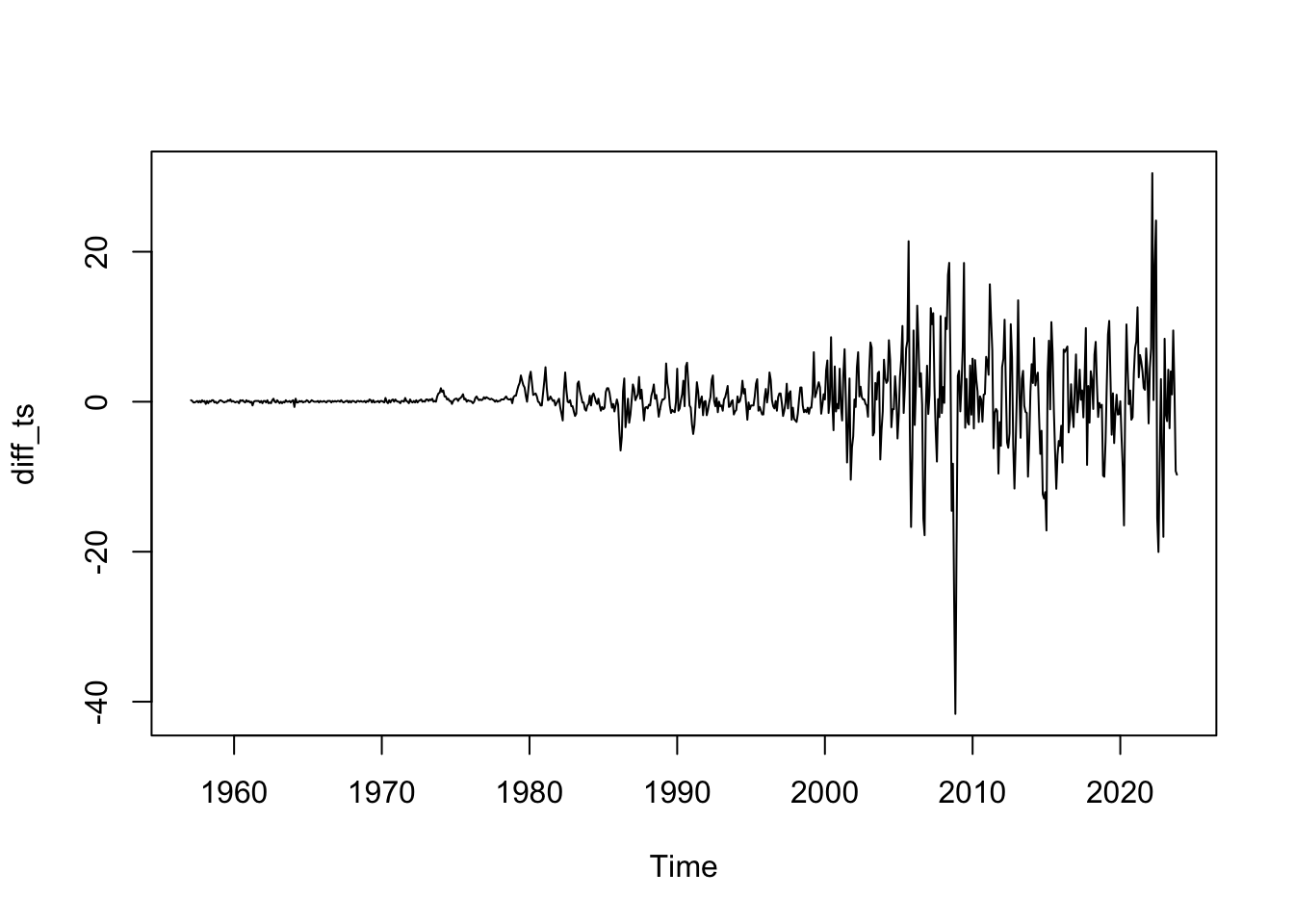
ARIMA(0,1,0) : 4762.801
ARIMA(0,1,0) with drift : 4761.123
ARIMA(0,1,0)(0,0,1)[12] : 4751.105
ARIMA(0,1,0)(0,0,1)[12] with drift : 4750.212
ARIMA(0,1,0)(0,0,2)[12] : 4749.802
ARIMA(0,1,0)(0,0,2)[12] with drift : 4749.14
ARIMA(0,1,0)(1,0,0)[12] : 4748.883
ARIMA(0,1,0)(1,0,0)[12] with drift : 4748.184
ARIMA(0,1,0)(1,0,1)[12] : Inf
ARIMA(0,1,0)(1,0,1)[12] with drift : Inf
ARIMA(0,1,0)(1,0,2)[12] : Inf
ARIMA(0,1,0)(1,0,2)[12] with drift : Inf
ARIMA(0,1,0)(2,0,0)[12] : 4742.386
ARIMA(0,1,0)(2,0,0)[12] with drift : 4742.203
ARIMA(0,1,0)(2,0,1)[12] : Inf
ARIMA(0,1,0)(2,0,1)[12] with drift : Inf
ARIMA(0,1,0)(2,0,2)[12] : Inf
ARIMA(0,1,0)(2,0,2)[12] with drift : Inf
ARIMA(0,1,1) : 4581.902
ARIMA(0,1,1) with drift : 4581.821
ARIMA(0,1,1)(0,0,1)[12] : 4577.654
ARIMA(0,1,1)(0,0,1)[12] with drift : 4577.884
ARIMA(0,1,1)(0,0,2)[12] : 4573.756
ARIMA(0,1,1)(0,0,2)[12] with drift : 4574.212
ARIMA(0,1,1)(1,0,0)[12] : 4576.446
ARIMA(0,1,1)(1,0,0)[12] with drift : 4576.758
ARIMA(0,1,1)(1,0,1)[12] : Inf
ARIMA(0,1,1)(1,0,1)[12] with drift : Inf
ARIMA(0,1,1)(1,0,2)[12] : Inf
ARIMA(0,1,1)(1,0,2)[12] with drift : Inf
ARIMA(0,1,1)(2,0,0)[12] : 4568.379
ARIMA(0,1,1)(2,0,0)[12] with drift : 4569.08
ARIMA(0,1,1)(2,0,1)[12] : Inf
ARIMA(0,1,1)(2,0,1)[12] with drift : Inf
ARIMA(0,1,1)(2,0,2)[12] : Inf
ARIMA(0,1,1)(2,0,2)[12] with drift : Inf
ARIMA(0,1,2) : 4578.515
ARIMA(0,1,2) with drift : 4578.734
ARIMA(0,1,2)(0,0,1)[12] : 4575.644
ARIMA(0,1,2)(0,0,1)[12] with drift : 4576.08
ARIMA(0,1,2)(0,0,2)[12] : 4572.671
ARIMA(0,1,2)(0,0,2)[12] with drift : 4573.279
ARIMA(0,1,2)(1,0,0)[12] : 4574.772
ARIMA(0,1,2)(1,0,0)[12] with drift : 4575.261
ARIMA(0,1,2)(1,0,1)[12] : Inf
ARIMA(0,1,2)(1,0,1)[12] with drift : Inf
ARIMA(0,1,2)(1,0,2)[12] : Inf
ARIMA(0,1,2)(1,0,2)[12] with drift : Inf
ARIMA(0,1,2)(2,0,0)[12] : 4568.289
ARIMA(0,1,2)(2,0,0)[12] with drift : 4569.079
ARIMA(0,1,2)(2,0,1)[12] : Inf
ARIMA(0,1,2)(2,0,1)[12] with drift : Inf
ARIMA(0,1,3) : 4579.677
ARIMA(0,1,3) with drift : 4580.023
ARIMA(0,1,3)(0,0,1)[12] : 4577.191
ARIMA(0,1,3)(0,0,1)[12] with drift : 4577.708
ARIMA(0,1,3)(0,0,2)[12] : 4574.269
ARIMA(0,1,3)(0,0,2)[12] with drift : 4574.946
ARIMA(0,1,3)(1,0,0)[12] : 4576.379
ARIMA(0,1,3)(1,0,0)[12] with drift : 4576.941
ARIMA(0,1,3)(1,0,1)[12] : Inf
ARIMA(0,1,3)(1,0,1)[12] with drift : Inf
ARIMA(0,1,3)(2,0,0)[12] : 4569.998
ARIMA(0,1,3)(2,0,0)[12] with drift : 4570.839
ARIMA(0,1,4) : 4581.69
ARIMA(0,1,4) with drift : 4582.053
ARIMA(0,1,4)(0,0,1)[12] : 4579.221
ARIMA(0,1,4)(0,0,1)[12] with drift : 4579.733
ARIMA(0,1,4)(1,0,0)[12] : 4578.408
ARIMA(0,1,4)(1,0,0)[12] with drift : 4578.96
ARIMA(0,1,5) : 4583.72
ARIMA(0,1,5) with drift : 4584.063
ARIMA(1,1,0) : 4592.114
ARIMA(1,1,0) with drift : 4592.78
ARIMA(1,1,0)(0,0,1)[12] : 4590.795
ARIMA(1,1,0)(0,0,1)[12] with drift : 4591.591
ARIMA(1,1,0)(0,0,2)[12] : 4589.897
ARIMA(1,1,0)(0,0,2)[12] with drift : 4590.8
ARIMA(1,1,0)(1,0,0)[12] : 4590.336
ARIMA(1,1,0)(1,0,0)[12] with drift : 4591.158
ARIMA(1,1,0)(1,0,1)[12] : Inf
ARIMA(1,1,0)(1,0,1)[12] with drift : Inf
ARIMA(1,1,0)(1,0,2)[12] : Inf
ARIMA(1,1,0)(1,0,2)[12] with drift : Inf
ARIMA(1,1,0)(2,0,0)[12] : 4587.308
ARIMA(1,1,0)(2,0,0)[12] with drift : 4588.314
ARIMA(1,1,0)(2,0,1)[12] : Inf
ARIMA(1,1,0)(2,0,1)[12] with drift : Inf
ARIMA(1,1,0)(2,0,2)[12] : Inf
ARIMA(1,1,0)(2,0,2)[12] with drift : Inf
ARIMA(1,1,1) : 4577.984
ARIMA(1,1,1) with drift : 4578.289
ARIMA(1,1,1)(0,0,1)[12] : 4575.351
ARIMA(1,1,1)(0,0,1)[12] with drift : 4575.838
ARIMA(1,1,1)(0,0,2)[12] : 4572.434
ARIMA(1,1,1)(0,0,2)[12] with drift : 4573.078
ARIMA(1,1,1)(1,0,0)[12] : 4574.518
ARIMA(1,1,1)(1,0,0)[12] with drift : 4575.051
ARIMA(1,1,1)(1,0,1)[12] : Inf
ARIMA(1,1,1)(1,0,1)[12] with drift : Inf
ARIMA(1,1,1)(1,0,2)[12] : Inf
ARIMA(1,1,1)(1,0,2)[12] with drift : Inf
ARIMA(1,1,1)(2,0,0)[12] : 4568.139
ARIMA(1,1,1)(2,0,0)[12] with drift : 4568.95
ARIMA(1,1,1)(2,0,1)[12] : Inf
ARIMA(1,1,1)(2,0,1)[12] with drift : Inf
ARIMA(1,1,2) : 4579.966
ARIMA(1,1,2) with drift : 4580.292
ARIMA(1,1,2)(0,0,1)[12] : 4577.355
ARIMA(1,1,2)(0,0,1)[12] with drift : 4577.857
ARIMA(1,1,2)(0,0,2)[12] : 4574.418
ARIMA(1,1,2)(0,0,2)[12] with drift : 4575.085
ARIMA(1,1,2)(1,0,0)[12] : 4576.524
ARIMA(1,1,2)(1,0,0)[12] with drift : 4577.071
ARIMA(1,1,2)(1,0,1)[12] : Inf
ARIMA(1,1,2)(1,0,1)[12] with drift : Inf
ARIMA(1,1,2)(2,0,0)[12] : 4570.12
ARIMA(1,1,2)(2,0,0)[12] with drift : 4570.951
ARIMA(1,1,3) : 4581.695
ARIMA(1,1,3) with drift : 4582.053
ARIMA(1,1,3)(0,0,1)[12] : 4579.222
ARIMA(1,1,3)(0,0,1)[12] with drift : 4579.743
ARIMA(1,1,3)(1,0,0)[12] : 4578.411
ARIMA(1,1,3)(1,0,0)[12] with drift : 4578.979
ARIMA(1,1,4) : 4573.756
ARIMA(1,1,4) with drift : 4571.09
ARIMA(2,1,0) : 4579.505
ARIMA(2,1,0) with drift : 4579.69
ARIMA(2,1,0)(0,0,1)[12] : 4577.142
ARIMA(2,1,0)(0,0,1)[12] with drift : 4577.505
ARIMA(2,1,0)(0,0,2)[12] : 4575.062
ARIMA(2,1,0)(0,0,2)[12] with drift : 4575.574
ARIMA(2,1,0)(1,0,0)[12] : 4576.421
ARIMA(2,1,0)(1,0,0)[12] with drift : 4576.826
ARIMA(2,1,0)(1,0,1)[12] : Inf
ARIMA(2,1,0)(1,0,1)[12] with drift : Inf
ARIMA(2,1,0)(1,0,2)[12] : Inf
ARIMA(2,1,0)(1,0,2)[12] with drift : Inf
ARIMA(2,1,0)(2,0,0)[12] : 4571.428
ARIMA(2,1,0)(2,0,0)[12] with drift : 4572.095
ARIMA(2,1,0)(2,0,1)[12] : Inf
ARIMA(2,1,0)(2,0,1)[12] with drift : Inf
ARIMA(2,1,1) : 4579.893
ARIMA(2,1,1) with drift : 4580.248
ARIMA(2,1,1)(0,0,1)[12] : 4577.321
ARIMA(2,1,1)(0,0,1)[12] with drift : 4577.839
ARIMA(2,1,1)(0,0,2)[12] : 4574.356
ARIMA(2,1,1)(0,0,2)[12] with drift : 4575.04
ARIMA(2,1,1)(1,0,0)[12] : 4576.493
ARIMA(2,1,1)(1,0,0)[12] with drift : 4577.055
ARIMA(2,1,1)(1,0,1)[12] : Inf
ARIMA(2,1,1)(1,0,1)[12] with drift : Inf
ARIMA(2,1,1)(2,0,0)[12] : 4570.052
ARIMA(2,1,1)(2,0,0)[12] with drift : 4570.9
ARIMA(2,1,2) : 4581.576
ARIMA(2,1,2) with drift : 4582.003
ARIMA(2,1,2)(0,0,1)[12] : Inf
ARIMA(2,1,2)(0,0,1)[12] with drift : Inf
ARIMA(2,1,2)(1,0,0)[12] : Inf
ARIMA(2,1,2)(1,0,0)[12] with drift : Inf
ARIMA(2,1,3) : Inf
ARIMA(2,1,3) with drift : Inf
ARIMA(3,1,0) : 4581.026
ARIMA(3,1,0) with drift : 4581.307
ARIMA(3,1,0)(0,0,1)[12] : 4578.438
ARIMA(3,1,0)(0,0,1)[12] with drift : 4578.91
ARIMA(3,1,0)(0,0,2)[12] : 4575.713
ARIMA(3,1,0)(0,0,2)[12] with drift : 4576.374
ARIMA(3,1,0)(1,0,0)[12] : 4577.627
ARIMA(3,1,0)(1,0,0)[12] with drift : 4578.148
ARIMA(3,1,0)(1,0,1)[12] : Inf
ARIMA(3,1,0)(1,0,1)[12] with drift : Inf
ARIMA(3,1,0)(2,0,0)[12] : 4571.48
ARIMA(3,1,0)(2,0,0)[12] with drift : 4572.324
ARIMA(3,1,1) : 4581.285
ARIMA(3,1,1) with drift : 4581.576
ARIMA(3,1,1)(0,0,1)[12] : 4578.762
ARIMA(3,1,1)(0,0,1)[12] with drift : 4579.224
ARIMA(3,1,1)(1,0,0)[12] : 4577.945
ARIMA(3,1,1)(1,0,0)[12] with drift : 4578.452
ARIMA(3,1,2) : 4568.698
ARIMA(3,1,2) with drift : Inf
ARIMA(4,1,0) : 4575.634
ARIMA(4,1,0) with drift : 4575.534
ARIMA(4,1,0)(0,0,1)[12] : 4574.175
ARIMA(4,1,0)(0,0,1)[12] with drift : 4574.312
ARIMA(4,1,0)(1,0,0)[12] : 4573.622
ARIMA(4,1,0)(1,0,0)[12] with drift : 4573.812
ARIMA(4,1,1) : 4556.801
ARIMA(4,1,1) with drift : 4554.628
ARIMA(5,1,0) : 4561.352
ARIMA(5,1,0) with drift : 4560.508
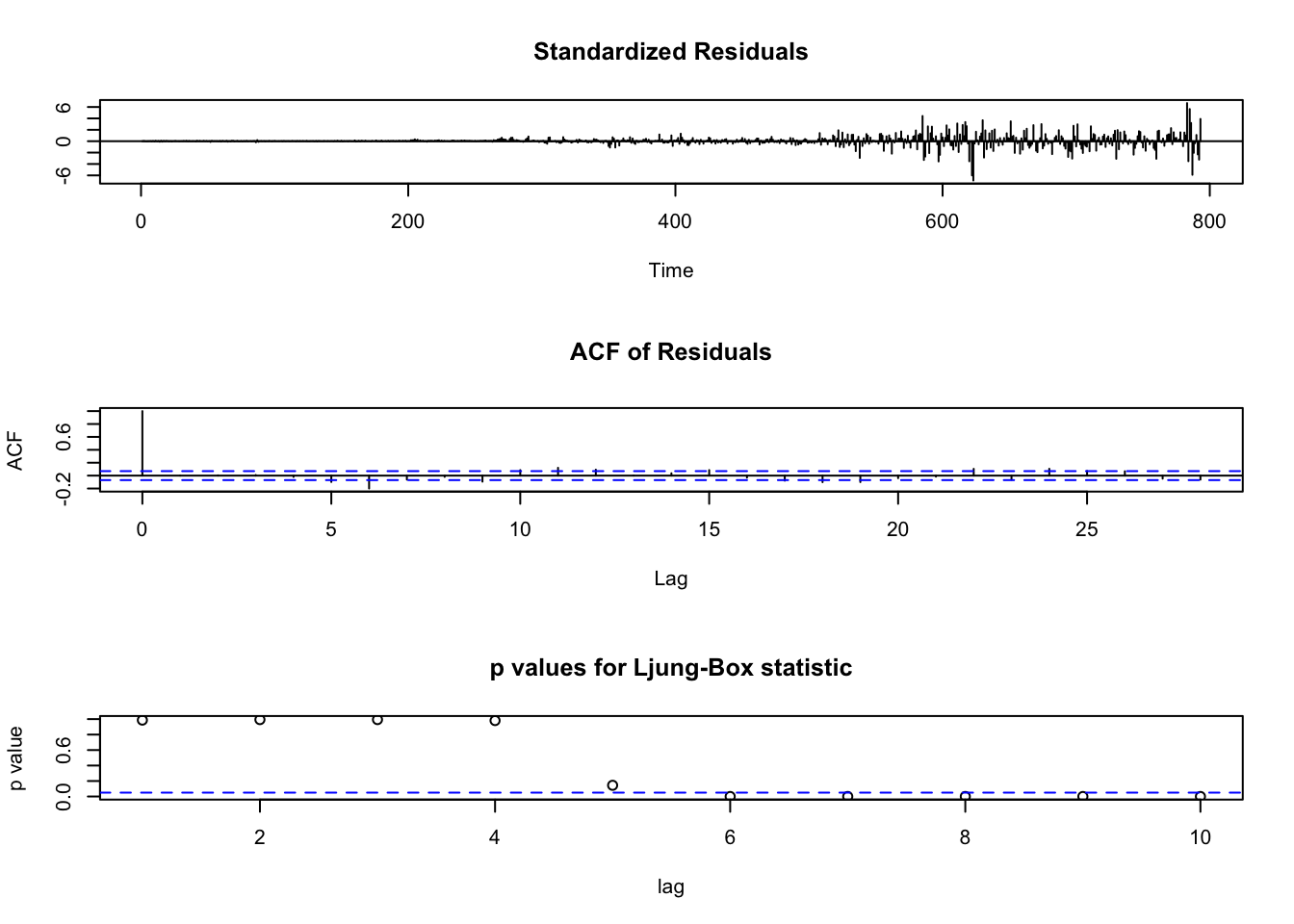
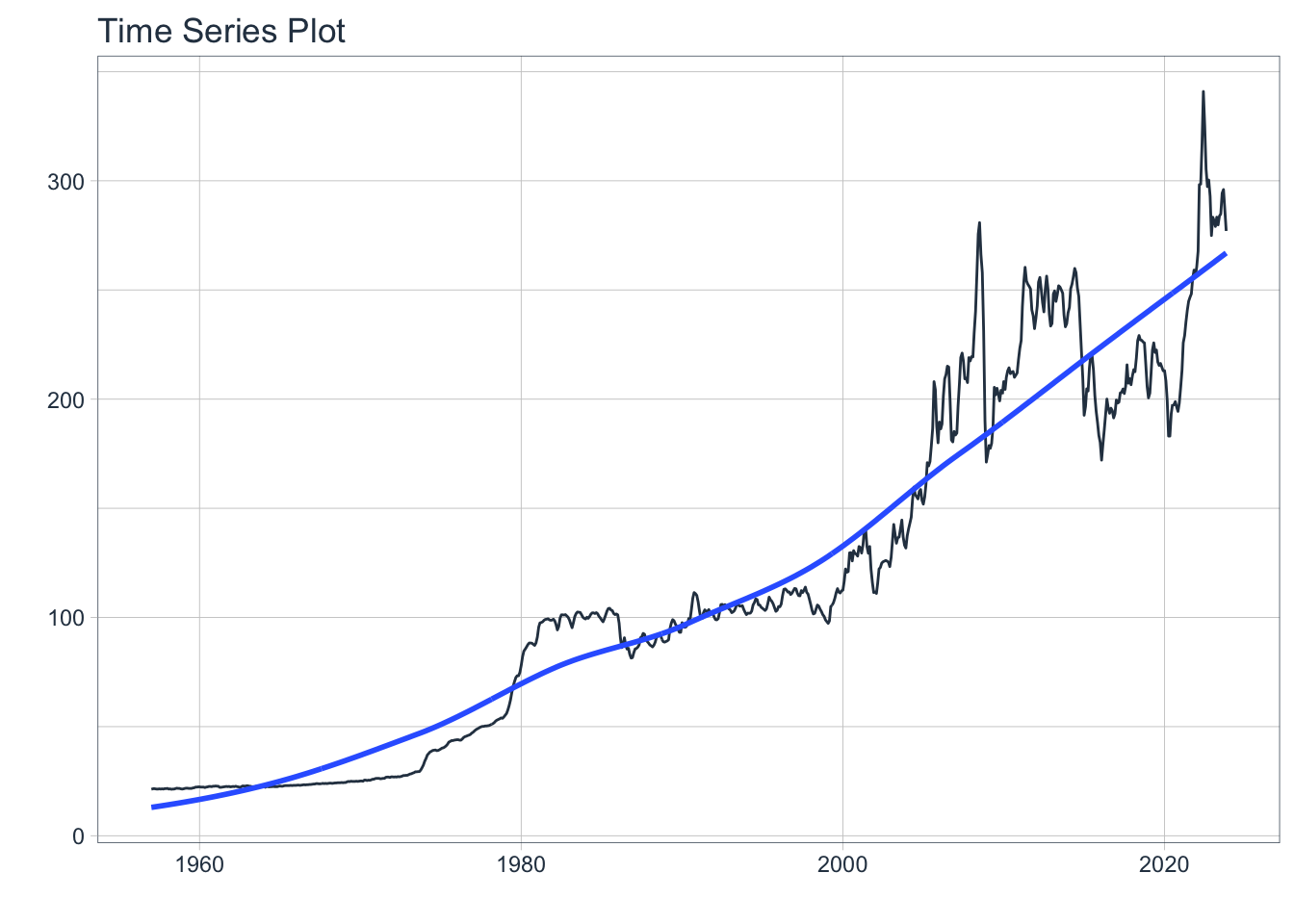
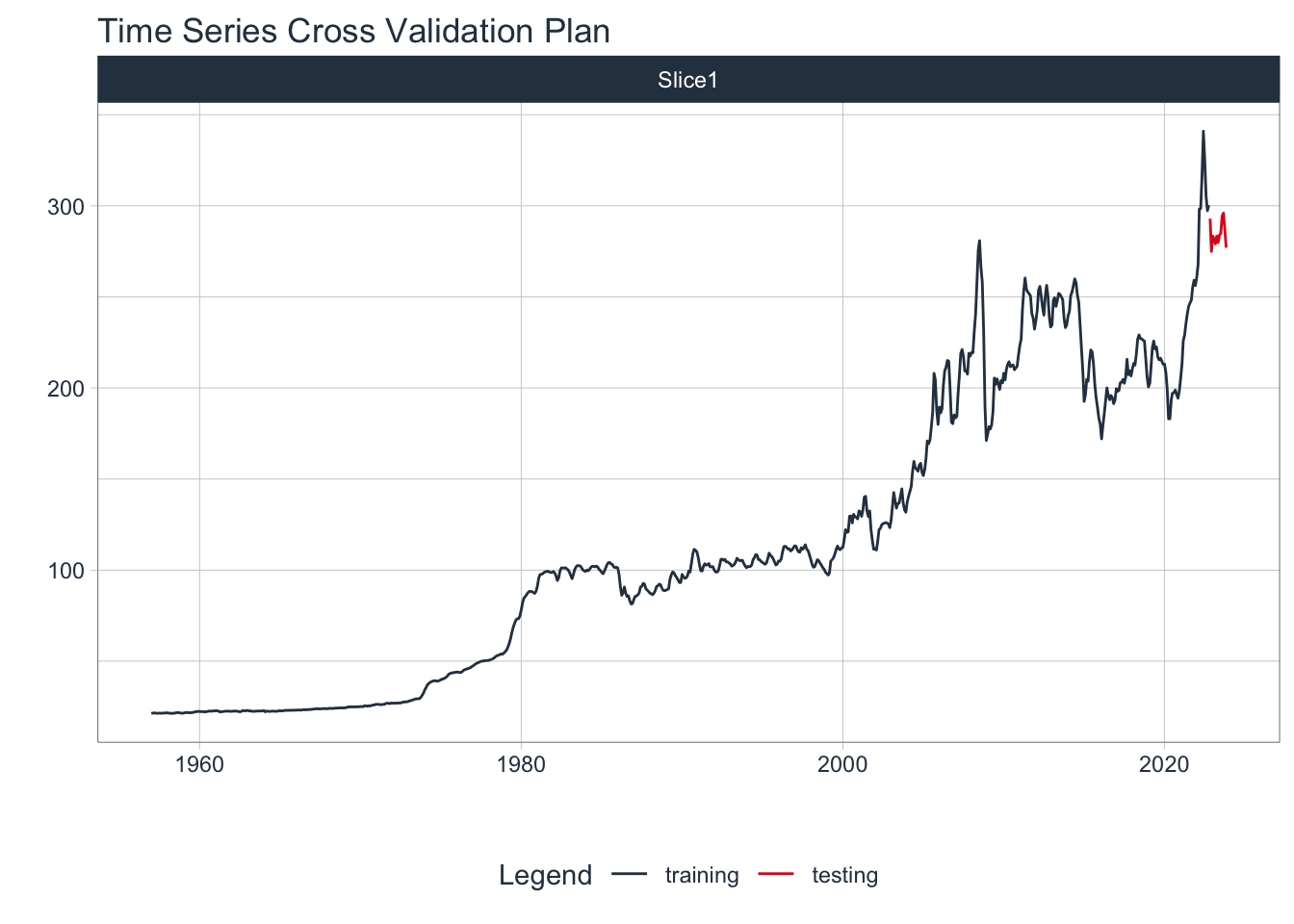
Best model: ARIMA(4,1,1) with drift