First post on portfolio optimization from a quantitative finance lense.
We are optimizing a portfolio with N assets, where \(N \geq 2\) (N is a positive integer)
Definition 1 The weight of each assets i in the portfolio is defined as:
\[ W_i = \frac{\mbox{Market value of asset i}}{\mbox{Total market value of portfolio}} \tag{1}\]
Of course, the sum of all the weights should be equal to 1.
\[\sum_{i = 1}^{N} W_i = 1 \tag{2}\]
Few assumptions made on the assets.
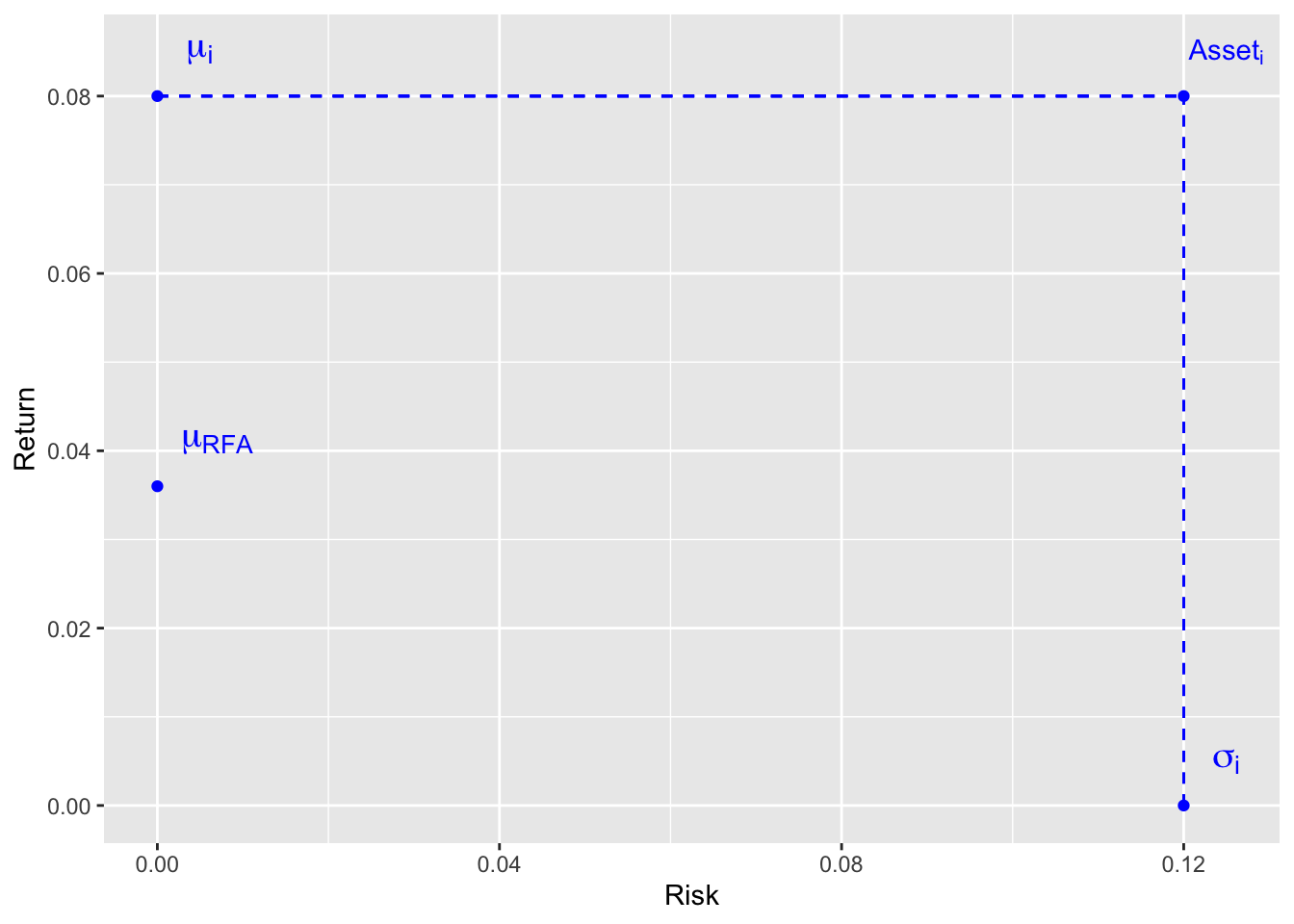
- each asset has an expected return denoted by \(\mu_i \mbox{ with } i = 1, 2, \ldots, N\). In that sense \(\mu_i = E[R_i]\)
- each asset has standard deviation on their returns denotated by \(\sigma_i \mbox{ with } i = 1, 2, \ldots, N\)
- the correlation between asset i and asset j is denoted by \(\rho_{ij} \mbox{ with } i,j = 1, 2, \ldots, N\). In that sense, \(\rho_{ij} = corr(R_i, R_j)\)
The Mean-Variance Optimization problem can be formulated in 2 ways:
- Highest possible returns for a given amount of risk
- Lowest possible amount of risk for a given expected return
Return is the expected return of the asset and risk is the variance of the returns of the asset.
The Risk-Free Asset (RFA) is the money deposited in a bank account-ish (a secure term-deposit) at a fixed rate R. The expected return is thus R and volatitliy is 0. Also the correlation between the RFA and any other assets is 0.
Each asset can be represented on a 2D-plane with the risk on the x-axis and returns on the y-axis.
There are some other assumptions made when trying to construct a mean-variance optimum portfolio:
- results are based on total returns (include dividends, interest paid, etc.)
- fractional shares are possible
- can deposit and withdraw money freely at the risk-free rate
- no restriction on short selling
- doesn’t account for tax, transaction fees, collateral and margins.
In practice
To bring these idea into practices, there are a few ways to go about it. The first approach is to have Monte-Carlo simulations using historical data for the parameters of the mean and variance. Another approach would be to use numerical methods to find the optimum weights that maximize the sharpe ratio (aka ratio of returns to volatility). In this way, we’ll find the efficient frontier: aka the best returns for a given risk or a lowest risk for a given returns.
Create MC simulations of weights to assess mean-variance of a portfolio
Let’s get 5 different financial assets: AA, LLY, AMD, SBUX, FDX. Although they are from different industries, it is not a very diverse bunch as they are all from US big companies.
We already have the assets downloaded and we’ll use their closing prices.
library(readr) # read_csv()
library(dplyr) # select(), arrange(), filter(), mutate(), summarize()
library(purrr) # map()
library(tidyr) # drop_na(), pivot_wider(), unnest()
library(glue) # glue()
library(lubridate)
# read adjusted closing prices and compute annualized daily returns and sd
read_prices <- function(ticker) {
df <- read_csv(glue('../../../raw_data/', {ticker}, '.csv')) |>
arrange(date) |>
select(date, adj_close = adjClose) |>
filter(date > '2018-01-01') |>
mutate(ret1d = (adj_close / lag(adj_close, 1)) - 1) |>
summarize(mean_ret = mean(ret1d, na.rm = T) * 252 * 100,
std_ret = sd(ret1d, na.rm = T) * sqrt(252) * 100)
return(df)
}
assets <- c('AA', 'AMD', 'FDX', 'SBUX')
df <- tibble(ticker = assets,
prices = map(ticker, read_prices)) |>
unnest()| Ticker | Mean Ret | Std of Ret |
|---|---|---|
| AA | 15.90 | 60.72 |
| AMD | 55.20 | 56.37 |
| FDX | 4.40 | 37.53 |
| SBUX | 16.43 | 30.36 |
First, we create the df of returns:
- it’s a long df with only ticker, date, daily returns
- one row per daily observation.
- we drop first row with no returns
- the returns df is a wide df with date and tickers as columns, then daily returns as row
# functions to get daily returns of each assets
create_returns_df <- function(ticker) {
df <- read_csv(glue('../../../raw_data/', {ticker}, '.csv')) |>
arrange(date) |>
select(date, adj_close = adjClose) |>
filter(date > '2018-01-01') |>
mutate(ret1d = (adj_close / lag(adj_close, 1)) - 1) |>
select(date, ret1d)
}
# df of each assets and all their daily returns
df <- tibble(ticker = assets,
prices = map(ticker, create_returns_df)) |>
unnest(cols = c(prices)) |>
drop_na()
returns <- df |> arrange(ticker) |>
pivot_wider(names_from = ticker, values_from = ret1d)
head(returns)# A tibble: 6 × 5
date AA AMD FDX SBUX
<date> <dbl> <dbl> <dbl> <dbl>
1 2018-01-03 -0.0121 0.0519 0.0125 0.0187
2 2018-01-04 0.00367 0.0494 0.0156 0.00375
3 2018-01-05 -0.0112 -0.0198 0.00393 0.0115
4 2018-01-08 0.0168 0.0337 0.0103 -0.00503
5 2018-01-09 -0.0145 -0.0375 -0.00339 -0.00219
6 2018-01-10 0.0363 0.0118 0.000971 0.0108 To optimize the mean-variance of the portfolio, we consider the following
Weights of each assets are \(w = \pmatrix{w_1 \\ w_2 \\ \vdots \\ w_n}\).
Mean returns of each assets are \(\mu = \pmatrix{\mu_1 \\ \mu_2 \\ \vdots \\ \mu_n}\)
Then, the expected portfolio return is \(\mu_{\pi} = w^{T} \cdot \mu\) where \(w^{T}\) is the transpose of \(w\) (aka transforming \(w\) from a column vector to a row vector in order to have right dimensions to compute the dot product).
And the expected portfolio variance is computed by \[\sigma_{\pi}^2 = w^T \cdot \Sigma \cdot w\] where \(\Sigma\) is the covariance matrix. Also, don’t forget to square root the variance when using sd: \(\sigma_{\pi} = \sqrt{w^T \cdot \Sigma \cdot w}\)
To put this into code, we first create the matrix of returns,then create the covariance matrix. Using both matrices, we create a function that return the portfolio mean and variance using the randomly chosen weights.
# this df to provide vectors of expected returns
df_stat <- df |>
group_by(ticker) |>
summarize(mean_ret = mean(ret1d, na.rm = T) * 252) |>
ungroup() |> arrange(ticker)
mu = as.matrix(df_stat$mean_ret, nrow = length(assets))
# this df to provide the covariance matrix
# note how we have also multiplied it by 252
sigma <- df |> arrange(ticker) |>
pivot_wider(names_from = ticker, values_from = ret1d) |>
drop_na() |>
select(-date) |> cov() * 252
sigma <- as.matrix(sigma, nrow = length(assets))
# this function to create one simulation using random weights
create_one_portfolio_simulation <- function(n) {
# pick random weights
weights_rand = runif(length(assets))
weights = matrix(weights_rand / sum(weights_rand), nrow = length(assets))
#these are textbook formula for return and volat of a portfolio
return_pi = as.numeric(t(weights) %*% mu)
volat_pi = sqrt(as.numeric((t(weights) %*% sigma) %*% weights))
sharpe_ratio = return_pi / volat_pi
# wrap everything into a df for later checks / analysis
df <- tibble(portf_ret = round(return_pi * 100, 4), portf_volat = round(volat_pi * 100, 4),
weights = round(t(weights) * 100, 4), sharpe_ratio = sharpe_ratio)
return(df)
}
#this is really the only inputs to get
num_portfolio = 7000
mc_simu = tibble(id = 1:num_portfolio) |>
mutate(simul = map(id, create_one_portfolio_simulation)) |>
unnest(cols=c(simul)) |>
arrange(desc(sharpe_ratio))
head(mc_simu)# A tibble: 6 × 5
id portf_ret portf_volat weights[,1] [,2] [,3] [,4] sharpe_ratio
<int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 5514 46.1 47.0 1.90 76.7 0.384 21.0 0.980
2 2576 43.8 45.0 2.75 71.3 2.32 23.7 0.973
3 3671 39.8 40.9 0.729 60.5 0.363 38.4 0.973
4 4718 41.1 42.3 2.24 64.1 1.31 32.4 0.973
5 3150 40.2 41.6 2.34 62.2 2.35 33.1 0.968
6 734 42.5 44.0 2.31 68.7 4.92 24.1 0.966Vizualisation of mean-variances points
We have highlithed the portfolio with best mean-variance returns with a red square around its dot.
library(ggplot2)
ggplot(mc_simu, aes(x = portf_volat, y = portf_ret)) +
geom_point(aes(colour = sharpe_ratio)) +
scale_color_distiller(palette="Set1") +
geom_point(data = mc_simu[1,], aes(x = portf_volat, y = portf_ret),
color = 'red', size = 6, shape=5) +
xlab('Portfolio Volatility') +
ylab('Portfolio Returns') +
labs(title = 'MC simulation for 5 stocks', color = 'Sharpe \n Ratio') 