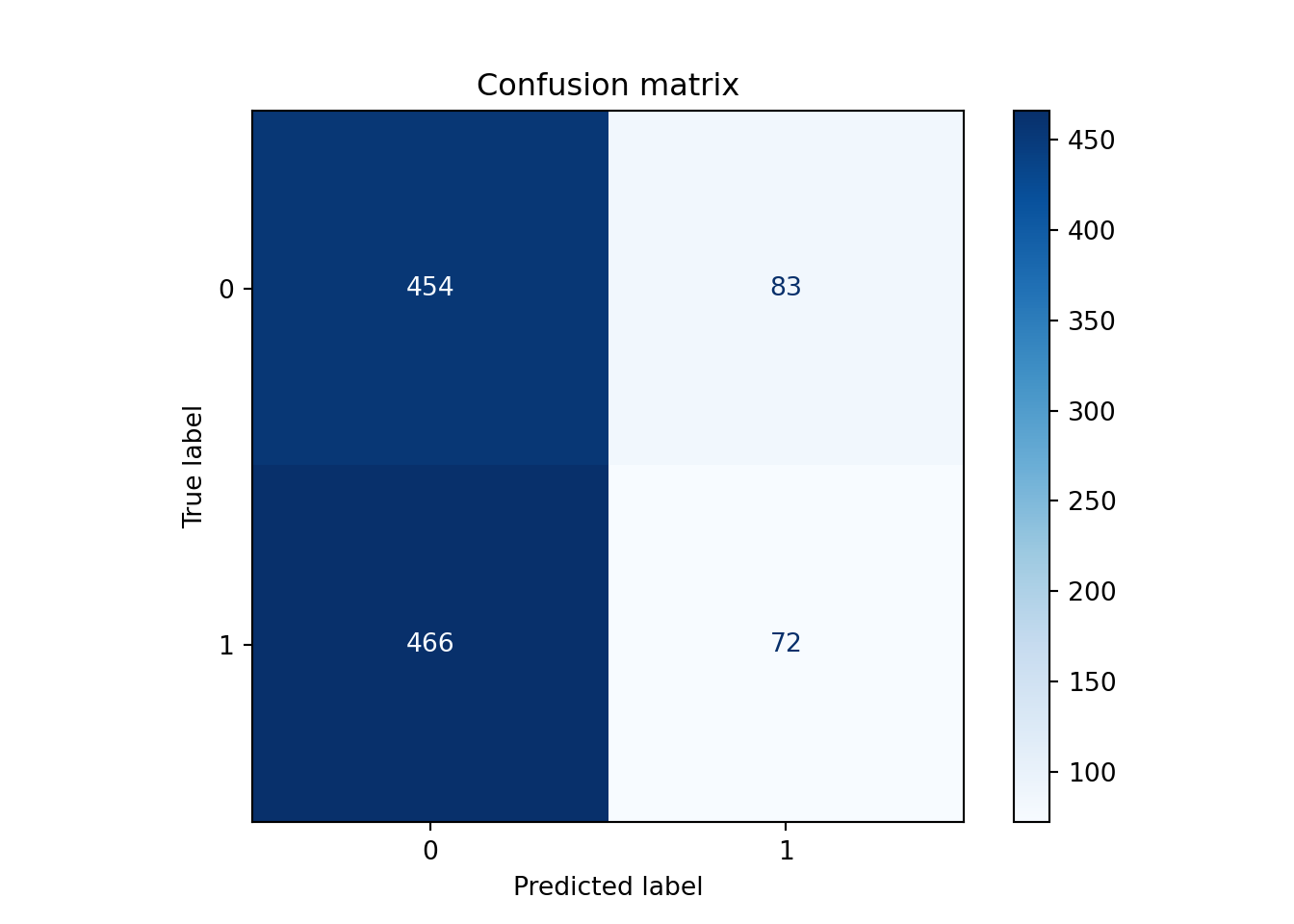
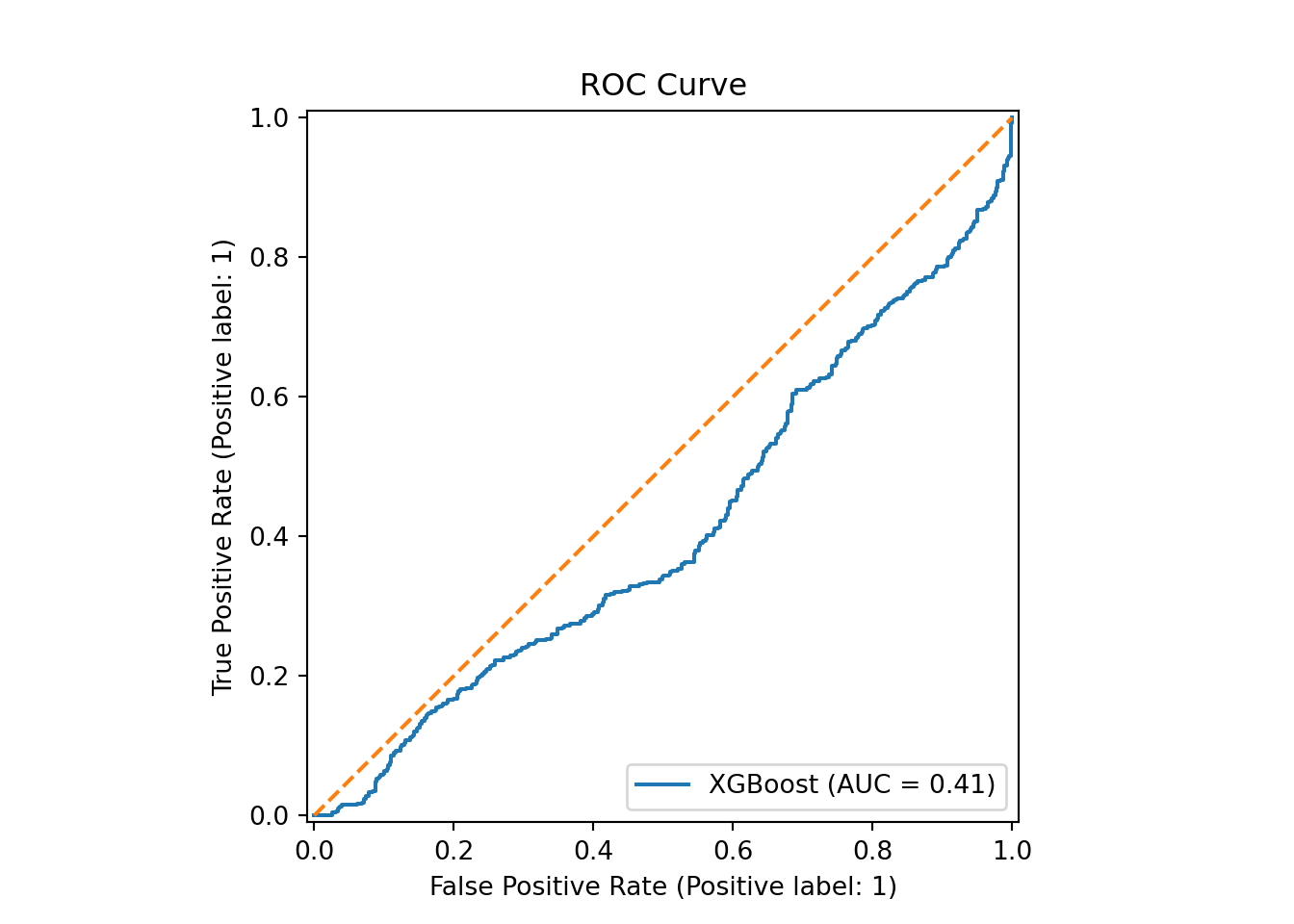
RandomizedSearchCV(cv=TimeSeriesSplit(gap=23, max_train_size=None, n_splits=5, test_size=None),
estimator=XGBClassifier(base_score=None, booster=None,
callbacks=None,
colsample_bylevel=None,
colsample_bynode=None,
colsample_bytree=None, device=None,
early_stopping_rounds=None,
enable_categorical=False,
eval_metric=None, feature_types=None,
gamma=None, grow_policy=...
monotone_constraints=None,
multi_strategy=None,
n_estimators=None, n_jobs=None,
num_parallel_tree=None,
random_state=42, ...),
n_iter=100,
param_distributions={'colsample_bytree': [0.3, 0.4, 0.5,
0.7],
'gamma': [0.0, 0.1, 0.2, 0.3, 0.4],
'learning_rate': [0.05, 0.1, 0.15, 0.2,
0.25, 0.3],
'max_depth': [3, 4, 5, 6, 8, 10, 12,
15],
'min_child_weight': [1, 3, 5, 7]},
scoring='f1', verbose=1)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.